PfSense actif/passif via ESXi
Obsolète : Cet article n’est plus maintenu. Les informations qu’il contient peuvent ne plus être à jour ou pertinentes. Si vous voulez redonder vos pare-feux, vous pouvez utiliser notre article sur la haute disponibilité
Une panne ayant mis hors d’usage notre pare-feu, nous avons du rétablir le réseau. Ayant prévu ce cas de figure, nous n’avons eu qu’à appliquer notre Plan de Reprise en brassant nos câbles.
Mais pour éviter que le problème ne se reproduise, nous avons mis à jours notre Plan de Continuité en mettant en place une configuration actif/passif, nous fournissant un pare-feu de secours près à prendre le relais.
À la suite d’une panne électrique dans le village, nous avons eu la surprise de voir notre pare-feu refuser de démarrer. N’ayant pas encore d’onduleur, on savait qu’une panne de ce genre nous pendait au nez mais on n’a beau s’y attendre, il a bien fallu réagir.
Comme des vrai pros, nous avons activé notre Plan de Reprise d’Activité et résolu le problème. Une fois l’orage passé (littéralement), nous avons mis à jour notre Plan de Continuité d’Activité pour éviter les dégâts la prochaine fois.

En parallèle de vous montrer les solutions que nous avons mises en place, cet article est aussi un prétexte pour vous présenter la différence entre ces deux plans de gestion des risques que tout bon RSSI est amené à formuler dans sa carrière.
Plan de Reprise d’Activité
Comme son nom l’indique, la reprise d’activité implique une perte temporaire de fonctionnement nécessitant des interventions pour reprendre un service. L’idée de ce plan est donc de prévoir les problèmes et leurs solutions à l’avance pour ne pas se retrouver dépourvu et surtout, gagner du temps lorsque ces risques ce concrétiseront.
Panne d’électricité et du pare-feu
Tout part donc d’un incident, plutôt banal : une coupure électrique. Pendant un orage, le réseau électrique a du être coupé et nos serveurs se sont donc arrêtés brusquement. Lorsque l’électricité est revenue, ils ont redémarré ainsi que nos machines virtuelles, dont le pare-feu pfSense.
Mais les choses ne sont pas bien passées pour lui. Lors de l’arrêt brutal, certains fichiers ont été corrompus et lorsque la machine a redémarré, elle est restée bloquée à l’étape « Starting DNS resolver ».
Centre névralgique du réseau, son indisponibilité bloque tous les flux, entre nos réseaux, mais aussi avec le reste du monde. Le site des arsouyes est injoignable, nous ne pouvons pas accéder à nos services ni à Internet. Le NAS étant dans le LAN, on pourra toujours regarder nos films et séries via la Mi Box. Mais c’est à peu près tout, pour l’instant.
Bascule sur le réseau de secours
Comme on s’attendait à ce type de panne – une indisponibilité du pare-feu – on avait prévu le coup et on savait déjà ce qu’on allait faire, dans l’immédiat du moins : Nous avons brassé la freebox sur le LAN.
En effet, lors de sa configuration, nous avions écarté le mode bridge au profit du mode routeur, nous fournissant ainsi un réseau fonctionnel à utiliser en cas de besoin. Et c’est justement ce dont nous avions besoin. Le LAN a donc retrouvé une plage d’adresse IP avec un serveur DHCP et une passerelle pour l’extérieur. Le reste du réseau n’est pas joignable, c’est donc un mode dégradé mais nos utilisateurs les plus importants (de 7 et 3 ans à l’époque) sont satisfaits. Temps de l’interruption : 5 minutes.
Nous avons ensuite pu prendre le temps de voir si le pare-feu était réparable, (divulgâchage : non), puis pris le temps pour en réinstaller un nouveau, 4 heures. Un rebrassage de la freebox plus tard et tout nos services sont en ligne comme avant.
L’opération aurait été encore plus rapide si nous n’avions pas repoussé la création des sauvegardes de configuration. Il aurait alors suffit d’importer la sauvegarde et le tour aurait été joué. Mais vous savez ce que c’est, on a toujours des choses plus importantes à faire…
Continuité d’Activité
Même si on peut se permettre de passer en mode dégradé et de prendre quelques heures pour réparer un pare-feu, c’est quand même mieux quand l’infrastructure est résiliente, minimisant les interventions humaines. Le Plan de Continuité d’Activité correspond plus à cette idée. Que le service continue de fonctionner, même pendant un incident. Ici, tout l’art est de trouver le juste milieu entre ce qui est réalisable et ce qui est nécessaire, ce qu’on appelle la gestion du risque.
Gestion du risque
La gestion du risque consiste à lister les problèmes qui peuvent survenir, mesurer leur criticité, les solutions possibles et, enfin, arbitrer en comparant le coût d’une solution et la criticité du risque qu’elle couvre.
- Lorsque ce rapport est acceptable, la solution est mise en oeuvre. Par exemple, pour éviter une coupure de l’accès internet, nous avons considéré que redonder nos connexions en vallait la peine.
- Lorsque ce rapport n’est pas acceptable, le risque est pris. Par exemple, concernant les pannes électriques, nous n’avons pas encore d’onduleur et il n’est pas prévu d’acquérir de groupe électrogène.
Pour revenir au pare-feu, nous acceptons que des pannes électriques éteignent notre infrastructure, mais nous aimerions que celle-ci puisse redémarrer sans problème. Et comme souvent, plusieurs solutions sont possibles.
La première est de passer en haute disponibilité. PfSense synchronisera alors automatiquement la configuration entre deux pare-feu et, en cas de panne sur le pare-feu principal, basculera le trafic sur le pare-feu secondaire. Par contre, cette solution nécessite d’utiliser deux machines physiques mais ne traite pas le redémarrage des deux instances… elle n’est donc pas adaptée à notre situation.
Nous avons donc opté pour une deuxième solution plus simple en mode actif / passif manuel :
- Actif : le pare-feu principal fonctionne mais ne démarrera pas automatiquement ;
- Passif : le pare-feu secondaire est éteint mais démarrera automatiquement ;
- Manuel : la synchronisation de la configuration est faite manuellement, ainsi que la reconfiguration des pare-feu après un redémarrage (ils échangent leurs rôles).
Nous pourrions bien sûr automatiser cette configuration. Un script pourrait surveiller le pare-feu principal, piloter ESXi pour échanger les pare-feu et même synchroniser les configurations. On pourrait même imaginer un échange de rôle quotidien, voir aléatoire – à l’image du Singe du Chaos – qui garantirait la résilience du système. Mais on a jugé que ça ne vallait pas la peine. Nous resterons donc sur un système manuel pour l’instant.
Redondance du pare-feu
Notre solution a donc besoin de deux machines virtuelles configurées de la même manière et pouvant se remplacer l’une l’autre.
Clonage des machines
La première étape consiste à redonder le pare-feu. Plutôt que de réinstaller une nouvelle machine, à l’image de l’ancienne, on a préféré la cloner, histoire d’avoir exactement la même configuration de départ.
Le clonage de machine n’est pas toujours disponible (e.g. sur l’interface web de la version gratuite d’ESXi 6.5.0). Il faut donc prendre un autre chemin pour y arriver. La première solution est d’exporter, puis d’importer la machine, ça marche mais les données passant par le réseau, ça prend du temps. Pour éviter les opérations réseaux, vous pouvez aussi copier le répertoire de la machine. Dans ce cas, voici les étapes :
- Mettre votre machine hors tension. Passez par le menu de gauche « Machines virtuelles », dans le tableau, sélectionnez votre machine puis cliquez sur le bouton « Mettre hors tension ».
- Copiez le répertoire de votre machine. Passez par le menu de gauche « Stockage » puis sur votre datastore. Cliquez sur le bouton « Navigateur de banque de données » et trouvez le répertoire de votre machine. Faites un clic-droit et choisissez copier, la fenêtre suivante vous demande la destination, renseignez-y le nom de votre nouvelle machine.
- Patientez. La copie peut prendre du temps, vous pouvez voir où elle en est dans le bandeau du bas « tâches récentes ».
- Enregistrez votre nouvelle machine. Via le
navigateur de banque de donnée, ouvrez le répertoire de votre machine,
faites un clic-droit sur le fichier
.vmxet choisissez « Enregistrer la VM ». Vous avez alors deux fois la même machine. - Renommez la nouvelle VM. Depuis le tableau des VM, cliquez sur chacune des VM et regardez l’emplacement du disque dur pour savoir laquelle est l’originale et laquelle est la copie. Depuis la copie, cliquez sur le bouton « Actions » et choisissez Renommer.
- Démarrez la nouvelle VM. Depuis l’écran de la nouvelle VM, cliquez sur « Mettre sous tension ». L’interface vous demande si c’est une copie ou un déplacement, répondez que c’est une copie.
À ce stade, vous disposez de deux machines équivalentes. Lors de ce premier démarrage, ESXi a adapté certains paramètres physiques comme l’adresse MAC (celle-ci devant être unique) pour que les deux machines puissent fonctionner de concert.
Configuration des adresses MAC
Comme nous utilisons du DHCP pour les réseaux WAN avec un bail statique pour le pare feu (cf. freebox et redbox), et que nous ne voulons pas vraiment changer ça, nous allons tricher pour avoir la même adresse MAC sur les deux machines.
Comme ESXi refuse de démarrer une machine si elle a une adresse MAC
déjà attribuée à une autre carte et dans le préfixe
réservé 00:50:56, nous allons leur attribuer des adresses
identiques dans un autre préfixe.
- Nous choisissons un préfix local, le deuxième bit doit donc
être à 1 mais comme ces adresses sont en petit boutiste, le
premier octet doit être multiple de 2. Les 22 bits restants sont à 0 ce
qui donne le préfixe
02:00:00.
C’est ce que dit la norme. En vrai, vous pouvez mettre ce que vous voulez dans les 22 derniers bits et les outils gèreront cette adresse sans problème.
- Ensuite, plutôt que de choisir les adresses, on a utilisé un générateur (e.g. celui de miniwebtool).
- Pour changer une adresse MAC, depuis l’écran de la machine on clique sur « Modifier ». On déroule ensuite la section de chaque Adapteur réseau, on change la configuration de l’adresse MAC de automatique à manuelle et on y entre la nouvelle adresse.
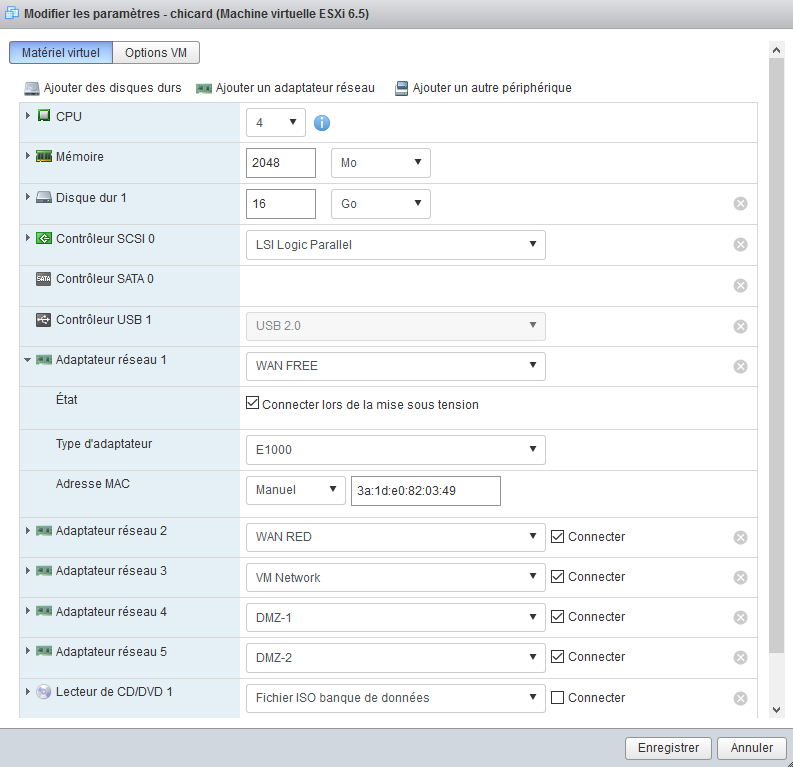
Une fois les deux machines configurées avec les mêmes adresses MAC sur chacune des cartes réseaux, les machines sont prêtes à se remplacer l’une l’autre. Si ce n’est pas déjà fait, il est nécessaire de reconfigurer le bail statique du DHCP côté WAN pour mettre à jour l’adresse MAC (e.g. freebox et redbox).
Configuration Actif / Passif
L’aspect actif / passif se règle très simplement. Allumez une des machines. Ensuite, via le tableau des machines virtuelle, faite un clic-droit sur chacune des machines et allez dans le menu « démarrage automatique ». Activez-le pour la machine en réserve et désactivez-le pour la machine en fonctionnement.
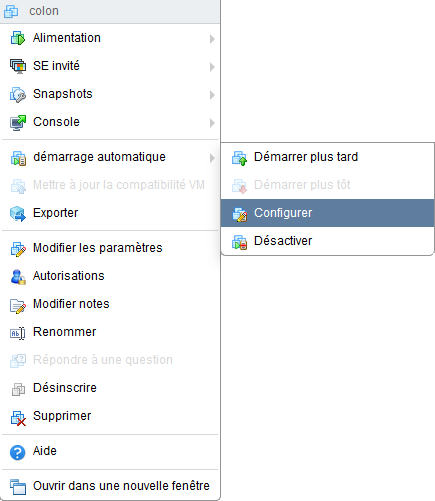
N’oubliez pas de changer l’ordre de démarrage automatique pour que votre pare-feu démarre avant les machines ayant besoin de son serveur DHCP (à moins que vous aimiez déboguer des problèmes de connexion IP). Cette action se fait via le même menu contextuel en cliquant sur « Démarrer plus tôt » autant de fois que nécessaire.
Pour tester, vous pouvez redémarrer votre serveur ESXi. Vous pourriez prendre la peine d’arrêter proprement vos VMs mais comme le but est de tester un arrêt brutal, vous pouvez aussi tout laisser tourner pendant l’arrêt… À vous de voir. Dans tous les cas, allez dans le menu de gauche, cliquez sur « Hôte » puis, en haut sur l’écran principal, sur « Redémarrer ». Puis patientez.
Une fois les machines démarrée, c’est le pare-feu de secours qui est en ligne et gère le trafic, l’autre étant éteint. Vous pouvez soit échanger les rôles, soit inverser la machine en fonctionnement, c’est vous qui voyez.
Synchronisation de la configuration
Comme on l’a dit, la synchronisation se fait manuellement. Lorsque la configuration du pare-feu actif change, il est nécessaire de la sauvegarder et de l’insérer plus tard dans le pare-feu de secours.
Pour sauvegarder la configuration, il faut passer par le menu « Diagnostique » puis « Backup & Restore ». Si vous voulez un fichier chiffré, cochez la case Encryption et renseignez un mot de passe (champ password). Vous pouvez alors télécharger la sauvegarde via le bouton « Download configuration as XML ».
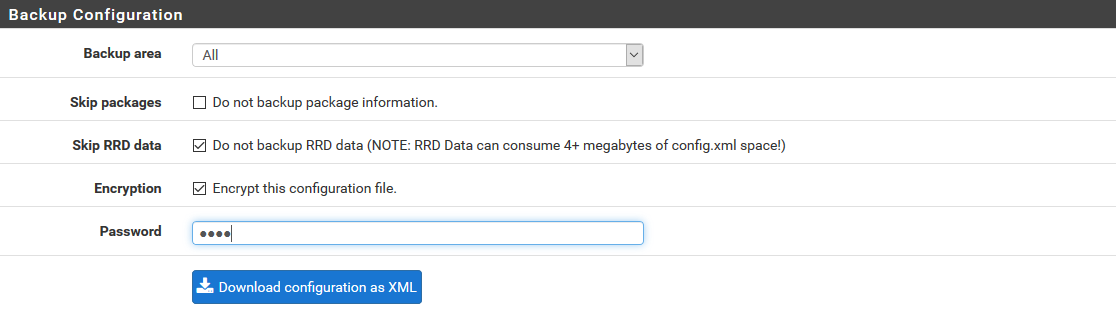
Lorsque vous modifiez votre configuration, suivant la nature de la modification, vous pouvez soit synchroniser tout de suite (en inversant les pare-feu), soit attendre un redémarrage.
Dans tous les cas, une fois le deuxième pare-feu en ligne, retournez sur la page de gestion des sauvegardes et dans la deuxième zone, ajoutez votre fichier (champ Configuration file) et si votre sauvegarde est chiffrée, cochez la case Encryption et renseignez le mot de passe (champ password). Cliquez alors sur le bouton « Restore Configuration ».
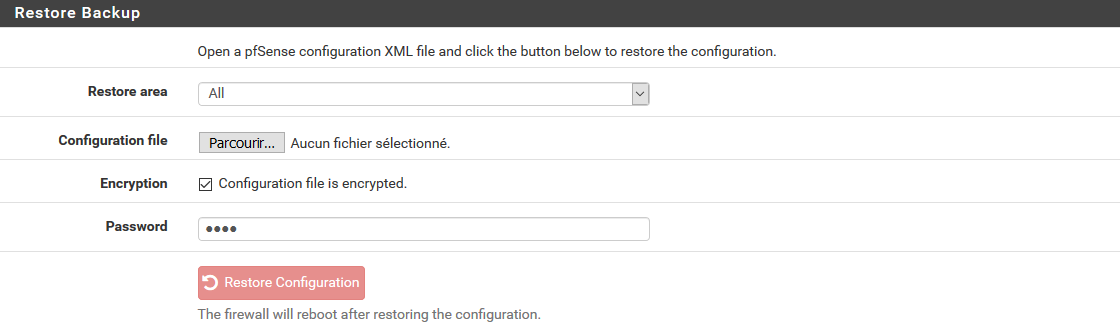
Et voilà ! Vous disposez de deux pare-feu équivalents dont l’un peut prendre la suite de l’autre et ne craignez plus les redémarrages intempestifs.
Et après ?
Avec un deuxième pare-feu prêt à prendre le relai, on est déjà plus tranquille. Pour continuer à configurer votre pare-feu :
- Cumuler les connexions, avec PfSense,
- Configurer les VLANs, avec un TP-LINK et ESXi,
- Supprimer les publicités, et enfin profiter des application.