Hash Functions: Checksums
Spoiler: Used to check data integrity, hash functions are everywhere. Today, we present to you the easiest of them, the checksums. The principle is simple, since any data is a sequence of 0 and 1, it is also a number that can be projected into a smaller set. Ideally, any change in the data will send it elsewhere and we will see the difference.
In a previous article on public key infrastructures, I briefly mentionned hash functions, but did not dwell on them. I have since realized that they are rather unknown. And it's a shame because even if we don't realize it, we use it all the time.
Before discussing their cryptographic version which was mentionned and which we will discuss in the next article, I would like to take a little time to introduce you to their ancestors: the checksums. Much simpler, they already have the fundamental characteristics of hash functions.

It all starts with a simple and fairly common IT (security) need:
How to check that data has been transmitted without being altered?
Whether we are transmitting a packet over a network, storing important files, or copying a seal. How de we make sure that there was no problem and that the data received is indeed consistent with the original?
Global parity bits
Let's start with the most rudimentary method: count the number of
bits that are worth
,
if this number is even, we add a
,
if it is odd, we add a
.
Mathematically, it is to make an exclusive or of all the bits
of the message. It is written XOR in the text (for
eXclusive OR) ,
in math and ^ when programming.
| Data | |
|---|---|
| 00 | 0 |
| 01 | 1 |
| 10 | 1 |
| 11 | 0 |
| 011010011100110101 | 0 |
In terms of projection, it reduces everything to only two possible values: 0 or 1. A bit radical for a hash but if a single bit changes in the data, the parity will change too and we can detect this error 🎉.
On the other hand, and this is where it is somewhat limited, if two bits change, it will no longer be detected.
Parity bits on words
To go further, we can cut the message into parts of the equal length (called words) and add their parity bit to each one. We can then detect several errors (as long as they appear in different words).
In Real Live, in ASCII. In the past, each character was encoded with 7 bits. We could then code 128, which was considered largely sufficient at that time. The 8th bit, because data was already handled in 8-bit words, could be used for parity and thus detect transmission errors.
| Letter | 7bits ASCII | Parity | 8bits ASCII |
|---|---|---|---|
| B | 1000010 |
2 | 01000010 |
| o | 1101111 |
6 | 01101111 |
| n | 1101110 |
5 | 11101110 |
| j | 1101010 |
4 | 01101010 |
| o | 1101111 |
6 | 01101111 |
| u | 1110101 |
5 | 11110101 |
| r | 1110010 |
4 | 01110010 |
The message Bonjour, although only using 49 bits for its
encoding, will actually use 56 for its storage and
transmission. You can think of those extra 7 bits as a form of hashing,
but since it's spread throughout the message, it's not practical to
extract and use globally.
The schism of 1981 was triggered when heretics decided to use this bit to produce blasphemous 256-character extended ASCII. Each new sect then producing its share of new characters, not always compatible with each other. IBM with EBCDIC, Europeans with ISO-8859-1, some Westerners with windows-1252, …
After years of encoding disputes, and the use of conversion tools (i.e.
iconv), 1991 marked the end of the war with an ecumenical proposal for the reunification of peoples: unicode, which would put decades to prevail.Since then, things have settled down and we can finally exchange emoticons without being afraid that they are badly decoded. For their interpretation, on the other hand, we have not decided.
Parity Words
In some systems, rather than computing the parity for each word individually, it is calculated globally, performing a bitwise xor between all the words. The result is called parity word.
With an ASCII encoding, one could compute an xor of all the letters and thus produce a 7-bit parity word as well. You can think of it as doing an xor on each column. This is then a new ASCII character that can be added to the message.
| Letter | 7bits ASCII |
|---|---|
| B | 1000010 |
| o | 1101111 |
| n | 1101110 |
| j | 1101010 |
| o | 1101111 |
| u | 1110101 |
| r | 1110010 |
| ! | 1000001 |
That way, Bonjour, using 7 characters, can
usefully be supplemented with an 8th control
character: !. This character could be considered a hash of
the original message. Well, in real life, we don't use this technique on
characters but on much longer words.

In Real Life, in RAID. This method is used when connecting hard disks in parallel to distribute the data. In RAID 3 (but also 5, 6, ...), one of the disks contains the bitwise xor of the other disks. This control disk has the advantage of making it possible to completely rebuild a failed disk.
It works because the xor with the bits form a commutative group a bit special where any data is in fact its own inverse. In our case, let's say you have your disks (noted ) and your control disk (noted ) which is the xor of the others, formally it looks like this: Since each data is its own inverse, we can also consider that the xor with the disks gives zero: As the operation is associative and commutative, we can, in fact, compute the xor in any order and we can therefore number the disks as we wish. If a disk fails, any disk but I'll name it for simplicity, you can re-order the list and then reverse the previous equations: Et voilà 😃, you can rebuild your disk. In fact, once the xor is done, mathematically, the discs become equivalent, each controlling all the others.
Sums
To continue, rather than a xor of the words of the message, we can also use a sum of the words of the message. We then approach this notion of checksum.
Since we work with words of fixed size, the result of the sum can be longer than the words (because of the carries). It is then necessary to choose how to manage these overflows: throwing them away silently is often the simplest, but as we will see, some people prefer to keep them and do something with them.
In Real Life, IPv4. When your computers communicate in the old-fashioned network, they forge IP packets containing, in their header, the IP address of your station, that of the destination and a whole lots of other cool data to do lots of fun things.
Among other headers, the checksum. To compute it, we cut the header into 16-bit words (i.e. two bytes) which are then added. Here, what overflows is considered as an additional word that is added later (and so on as long as there is a hold, but it ends up quickly). This is called a "1's complement addition". The result is then reversed (the become and vice versa). This is called a complement to 1, hence some confusion sometimes. The result is finally inserted in the right place of the message.
The interest of reversing this checksum is that the routers which will receive the message can simply compute a checksum of the complete header and check that the result is indeed zero. Mathematically, the principle is similar to the xor with previous hard drives.
For example: Here is a network capture during a ping
request (technically, an ICMP Echo Request) from my post
(192.168.1.149) to google.fr
(216.58.213.131), the part concerning the IP protocol is
selected and contains, among other headers, the checksum selected in
blue (here, 0x6917).
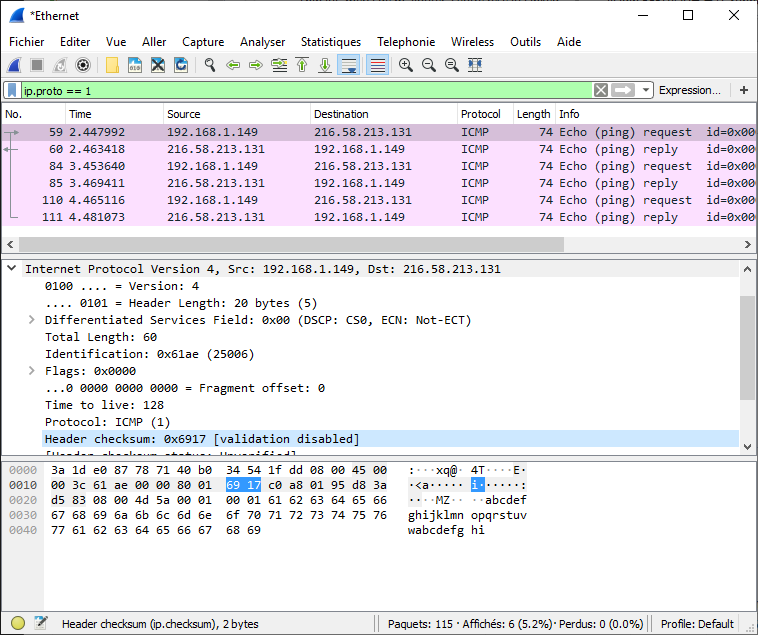
If we want to make sure that the header is correct, we must therefore add all the 16-bit words (i.e. 4 hexadecimal characters) of the IPv4 header, without taking into account the other headers (here Ethernet and ICMP) nor the data (content of the ICMP request). All this, taking into account these complementary stories...
The following table shows you this calculation:
| Header (value) | Hexa |
|---|---|
| Version (4), Header size (5), type (0) | 4500 |
| total size (60) | 003C |
| ID | 61AE |
| Flags and offset (0) | 0000 |
| TTL (128) and protocol (1 for ICMP) | 8001 |
| Checksum | 6917 |
| Source (first half 192.168) | C0A8 |
| Source (second half 1.149) | 0195 |
| Destination (first half 216.58) | D83A |
| Destination (second half 213.131) | D583 |
| Total (with carry) | 3FFFC |
| Carry only | 3 |
| 1's complement addition | FFFF |
| Complement to 1 | 0000 |
And as things are well done, this complement to 1 of the total complemented to 1 is indeed zero and the packet is valid. No surprise since this request had received a response (or rather an ICMP echo reply).
Note that ICMP also inserts a checksum computed in exactly the same way on its own headers.
In IPv6 things have changed and there is no more checksum.
The engineers have indeed noted that integrity checks were already made by the lower layers, called link layers like Ethernet or WiFi, but also by the upper layers, called transport layers like TCP and UDP, which both have a checksum (computed exactly as for IP and ICMP) but whose scope also overflows on part of the IP headers.
To be clean, we should have fixed TCP and UDP to avoid doing a checksum on the IP headers (since they are two different layers, they should not depend on each other) but as it is very expensive to change a protocol and as a solution had to be found to the shortage of IPv4 addresses (we are in the 90s), we preferred to change only the IP layer by producing IPv6.
Decimal divisions
The problem with the previous methods is that if some words are moved to another order, they are not detected. This is the principle of commutative operations, it helps us a lot for hard disks, but it backfires in other cases.
Historically, these new methods were developed for digital data that was often manipulated by hand. Where the previous ones want to detect an electronic error (a change of bit), here, we try to detect human errors, with therefore inversions, wrong fingers, forgetting of digits...
To detect these errors of displacements, the idea is then to replace the notion of sum by that of division, keeping the remainder to be exact (mathematically, we also speak of modulo). Because it is the most sensitive to initial conditions: a small change in the data will normally produce a different modulo.
The trick is therefore to find the divisors that maximize the detected errors; change of individual digits anywhere (and sometimes groups of digits) and inversions between two digits (side by side or at a certain distance).
In Real Life, the national identification number. This number, which makes it possible to identify a person and attach rights and duties to him, is often constructed from civil status.
- In France, we use one number for gender (1 for girls, 2 for boys), four for date of birth (2 for year, 2 for month), 5 for place of birth (2 for the department, three for the city) and finally 3 for the serial number.
- In Belgium, 6 digits are used for the date of birth (2 for the year, 2 for the month, 2 for the days) then three for the serial number (with an odd counter for boys and another even for the girls).
For these two countries, then follows a validation key () on two digits. This key is the 97's complement of the remainder of the division of the number () previously formed by 97:
To be completely exact, in Belgium, if you were born after the year 2000, we will add a 2 at the beginning of the number. Just the time for the computation since this 2 does not officially appear in your number.

For example. If we take the example social security number from the Wikipedia page, Nathalie Durand, 157th baby born in May 1969 in a non-existent town in Maine et Loire.
Its registration number is therefore 2 69 05 49 588 157. If we compute the integer division by 97, we get the following result:
That is a remainder of 17. The key being in fact the complement of 97, we obtain a key of 80 as follows:
There is also a modulo 97 in the ISO 7064 standard, used among other things for international bank account numbers (IBAN). After some manipulation (including inserting a null key) we then compute the complement to 98 of the remainder of the division by 97:
The advantage of this method is, as for IPv4, that the verification is done by computing a key on the given data (already containing a valid key, therefore). The advantage of using 98 is that a calculated key is worth at least 1, different from the empty key inserted during the computation.
Binary divisions
With binary data, we could keep the same principle but their length and especially the management of carries become difficult to handle. To simplify all that, we will then replace the sum by a xor which has the good taste not to have any carries. To be programmed or wired, it is much more practical.
Mathematically, we change the set for the calculations: instead of the usual ring , we will use . The xor replaces the sum.
On the other hand, even if the principle of the computation remains the same, since one of the two basic operations is changed, the results are different. See for yourself in the following table where the first column is in decimal (with asterisk as operator $ *$ ) and the following columns are in binary but one with the sum, the other with the xor.
| or |
Likewise, division keeps the same meaning; compute the inverse of the multiplication. But its computation (and therefore its result) changes. You can do the tests by writing your divisions as in primary school.
And as for the validation keys of identification numbers, the whole art of the computer scientist is to choose a divisor that will maximize the errors detected. Among other things, a divisor using bits will always have a remainder that fits on bits. If you want a 32-bit remainder, then you need a 33-bit number.

In Real Life, CRCs. These cyclic redundancy codes were invented in the 60s and follow this principle of dividing a piece of data, keeping the rest and checking that it is the same as the one transmitted.
When we talk about CRC, we associate binary data with polynomials. Each bit of the message being the coefficient of the corresponding polynomial term. Here are some examples :
| Data | Polynomial |
|---|---|
Rather than using the ring , we then use that of polynomials with Boolean coefficients . Computations and data are then expressed in terms of polynomials. The chosen divisor can be thought of as a generator of all valid messages, and that sort of thing.
But as it works the same way, we can stay on numbers without introducing .
As there is a plethora of possible divisors (many of which are actually used), we took the convention of naming each case by the term CRC, followed by the size of the remainder (e.g. 32 when it is 32 bits) followed by the name of the divisor when it is not the default one.
By convention, as all divisors start with a
1and it appears one bit more than the size of the rest, we do not write it and we do not mention it. In fact, we can even do the computation without this 1...
For example, CRC-3-GSM is used in mobile networks.
It uses the divisor 3 (in base 10, in binary, it gives
11, and in real life, we therefore divide by
1011).
Another example, much more known, is the
CRC-32, which uses, by default, the divisor
0x04C11DB7. It is used, among other things, in Ethernet
frames (your RJ45 cables), Sata, gzip archives and PNG
images.
We also used this CRC-32 as an integrity check for the WEP protocol which was supposed to protect access to WiFi networks. Among its weaknesses, the use of this CRC in a computer attack context was not suitable since an attacker could forge his CRCs for his modified packets.
And now ?
The hash functions are in fact very numerous, as are their uses. For example, the preceding ping google actually implements at least three of these functions to check the integrity of the transmitted and received packet:
- A CRC-32 at the end of the Ethernet frame,
- A 1's complement of a 1's complement sum in the IP header,
- Another 1s-complement of a 1s-complemented sum in the ICMP header.
Similarly, a health insurance reimbursement will use one control key for your IBAN and another for your identification number. These payments using computer and telecommunications technologies, I let you imagine the number of checksums computed between the moment you go to your doctor and the moment you see the reimbursement on the web interface of your online bank...
And these are just checksums, to go further you can take a look at the cryptographic fingerprints…