Combien de robots ?
Il y a quelques jours, après avoir revu le style du site, je me suis demandé quelles pouvait être sa fréquentation. À une époque, nous avions mis en place des statistiques (e.g. Goaccess et Matomo) mais nous les avons supprimées depuis...
J’ai donc récupéré le log de la veille pour regarder moi-même ce qu’il y a dedans et me faire une idée. Avec quelques grep, sed, sort -u, wc et cie, je me suis mis à regarder les nombres et les tendances... Et je me suis rendu compte à quel point c’est difficile de se faire une idée tant il y a de bots dans la masse...
Plutôt que de tout trier à la main, je me suis dit que j’allais tenter une petite arnaque... j’ai modifié le CSS pour inclure une référence vers un logo bidon1. Les humains qui utilisent un navigateur chargeront l’image2, les robots qui lisent le contenu ne devraient pas la demander.
Après une journée complète de ce manège, j’ai supprimé la référence, récupéré les logs correspondants et voici ce que j’en ai tiré.
Données initiales
Le 15 janvier 2026, le site des arsouyes a journalisé 13 676 accès, provenant de 2 419 adresses IP et un volume de réponses3 de 987 Mo. Pour les curieux, voici les commandes que j’ai utilisées.
# Nombres d'accès :
wc -l access.log
# Nombre d'IP
sed -e "s/ .*//" access.log | sort -u | wc -l
# Volume envoyé
sed -e "s/.*1.1. ... //" -e "s/ .*//" access.log \
| grep -v "-" \
| awk '{s+=$1} END { print s}'Pour me faire une idée de ce que cette activité représente, j’ai utilisé Gource. Cet petit outil lit des journaux4 et vous anime tout ça dans une vidéo où l’arborescence du site se déploie au fur et à mesure que vos visiteurs (qui se baladent à l’écran) touchent les fichiers.
La distribution GNU/Linux que j’utilise5 ayant un paquet dans ses dépôts, je l’installe et je le lance sur mon fichier de log.
gource access.log -s 300J’ajoute l’option -s pour donner la durée d’une journée de log (ici 5 minutes), je m’assied confortablement et je profite du spectacle. J’y vois plein de monde qui s’active autour des fichiers RSS et, régulièrement, du monde qui vient peupler les diverses parties du site. À la fin, les bonshommes disparaissent et me laissent avec l’arborescence du site, tel qu’il a été consulté le 15 janvier 2026...
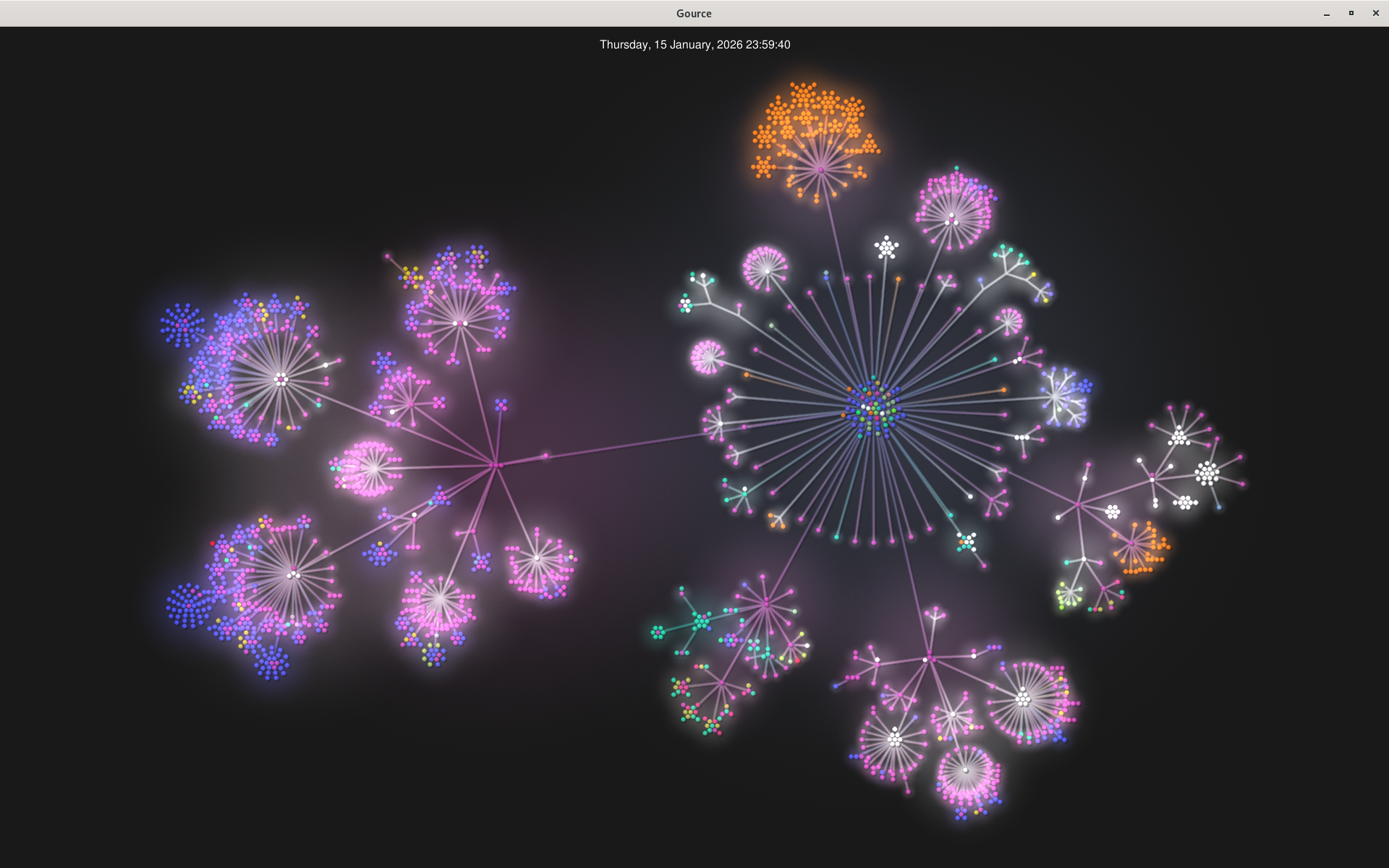
La racine du site est à droite de l’image (le centre avec les boules bleues, vertes, rouges, ...). La zone orange au nord correspond aux traductions de phrack (et ses fichiers au format TXT). Les articles sont sur la gauche (les points bleus sont des images et correspondent aux tutoriels). Globalement les zones en bas à droite correspondent à des répertoires (ou plutôt des chemins) qui n’existent plus ou ont été déplacés.
Premier filtre
Il est temps de se réveiller, fermer cette fenêtre et passer à la suite en filtrant les robots.
Comme je l’avais prévu, j’utilise le fichier /style/logo.png comme détecteur. Je commence par isoler ces accès dans mes logs, j’en extrait l’adresse IP et je met ce résultat dans un fichier pour plus tard.
grep "/style/logo.png" access.log | sed -e "s/ .*//" | sort -u > ips.txtJe peux maintenant filtrer mes logs d’accès pour ne garder que ceux des humains.
grep -f ips.txt access.log > access-human.logCe fichier comprend 963 accès répartis sur 124 adresses IP. Les personnes qui ont accédé à mon faux logo représentent 5% des visiteurs et 7% des requêtes. Visuellement, le tableau suivant vous illustre ces proportions…
| Proportion | |
|---|---|
| Accès | |
| Adresses |
Ce filtre n’est pas parfait et je m’attendais à des erreurs :
- Des faux positifs : des humains qui seraient vu comme des robots parce qu’ils utilisent des outils en ligne de commande. J’ai regardé les logs, mis à part
curl(utilisé pour scanner/wordpress/), aucun navigateur en ligne de commande n’est vu ce jour là (e.g.lynx,links,wget). - Des faux négatifs : des robots qui se seraient fait passer pour des humains. Et là, oui, il y en a. Plein plein plein.
Filtre manuel
Comme mon filtre automatique n’a pas filtré assez, je suis passé en manuel. J’ai regardé, pour chaque adresse IP qui a vu le fichier, quels sont les logs qui lui correspondent pour déterminer si c’est ou non un humain.
Certains annoncent qu’ils sont des robots dans les user-agent, mais d’autres ne jouent pas le jeu...
- Ils accèdent à des fichier (pas des pages ; des images, des PDF, le logo), avec un REFERER qui dit venir d’une page des arsouyes, et c’est là leur seule activité de la journée.
- Ils accèdent à des pages qui n’existent plus depuis plusieurs années et ne sont référencées nulle part sur le web.
- Des adresses IPv6 dont les 48 derniers bits sont à 0 ; ça flaire l’IP de grappes de serveurs avec adresse statique, ce ne sont pas des visiteurs mais des serveurs6.
Avec ce filtrage, il me reste 570 accès par 55 adresses. Plus de la moitié des adresses étaient des robots (mais ils ont généré moins de la moitié des requêtes).
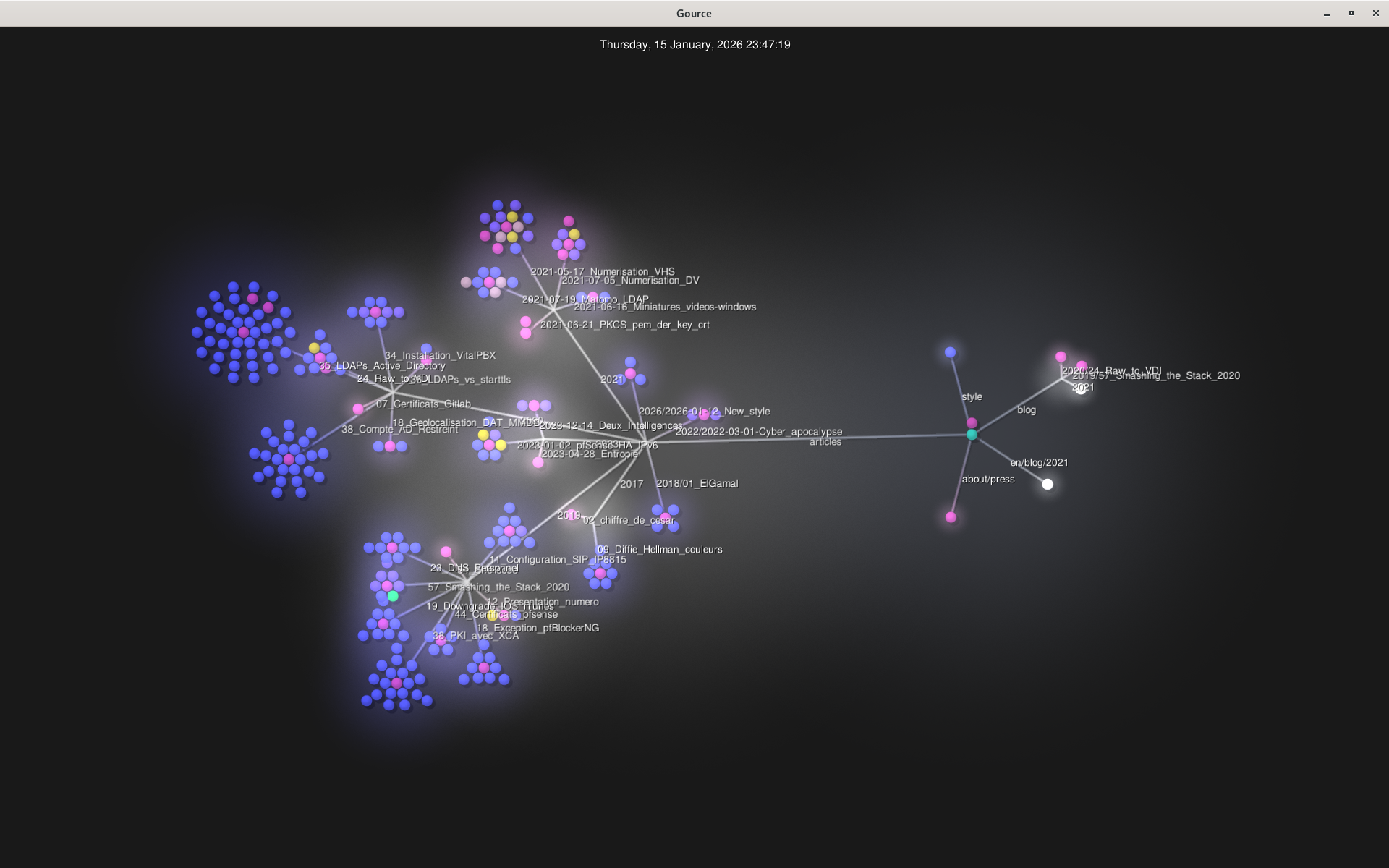
En gardant uniquement leur activité, je peux reprendre gource et contempler les gens venir nous rendre visite. C’est bien plus doux que tout à l’heure, et le résultat correspond bien mieux au site existant (les redirections et autres chemins oubliés sont bien plus rares).
Et après ?
Puisque les robots représentent 97.8% des visiteurs, je me suis dit que ça pourrait être intéressant de voir ce qu’il y a dans le tas. Ou plutôt de voir comment ça se réparti...
- Les lecteurs RSS. Ce sont effectivement des robots, mais ils viennent parce que des gens veulent savoir s’il y a du nouveau chez les arsouyes. Vu que d’autres robots viennent aussi lire le flux, je ne peux pas filtrer sur le fichier ; je les ai filtrés par leur
user-agent7, - Les robots d’indexation. Puisque le but du moteur de recherche est de m’envoyer des visiteurs ensuite, on peut se dire que ses robots sont utiles. Idem, j’ai filtré par
user-agent. - Les anmaerdeux (le reste). Des robots de SEO, des robots de sécurité (qui viennent me scaner alors que j’ai rien demandé), des robots d’IA (alors qu’on le leur a interdit) et autres petits malins.
Vous trouverez les chiffres dans le tableau suivant. Les robots d’indexation jouent le jeu, ils sont relativement peu nombreux (143 IP, soit 6%) et font peu de trafic, 319 requêtes (2,3 %) pour 22 Mo (2,2 %). Ce qui m’a surpris, c’est le RSS ; il sont à peine plus nombreux que les robots d’indexation mais génèrent 16 fois plus de requêtes et de trafic89.
| IPs | Accès | Volume | |
|---|---|---|---|
| Humains | 55 | 570 | 57 Mo |
| Indexation | 143 | 319 | 22 Mo |
| RSS | 204 | 5 310 | 356 Mo10 |
| Total | 2419 | 13 676 | 987 Mo |
Et si les chiffres vous sont difficiles à comparer, voici un graphique qui vous montre les proportions de chaque groupe suivant qu’on regarde le nombre d’adresses IP, de requêtes, ou le volume généré.
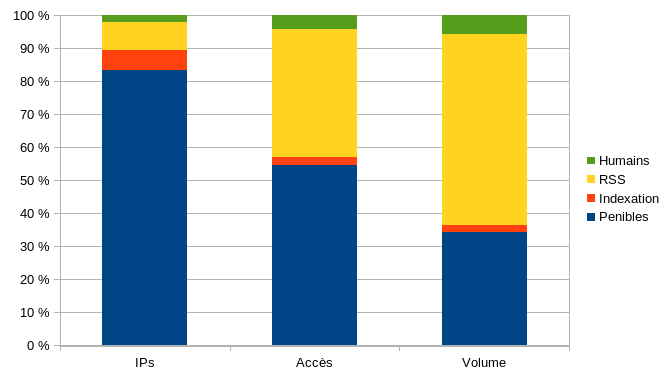
Initialement, on avait créé le site des arsouyes pour nous adresser à d’autres humains. On a vu les robots d’indexation comme des alliés pour permettre à ces humains de nous trouver. Finalement, on se rend compte que notre public principal ce sont des robots dont la plupart sont complètement débiles.