Backup with Books
Spoiler: Rather than messing with complex infrastructures or algorithms, why not save our content in books?
Last week, I wondered how to perform a denial of service and, of course, how to counter this kind of attack to ensure the service remains available despite the efforts of scunners who have nothing better to do.
But sometimes, a website is unavailable and it's no one's fault. Okay, fine, it's often someone's fault who made a blunder (and sometimes a few who produced an avalanche of blunders) but there wasn't always malicious intent...
Example with Cloudflare
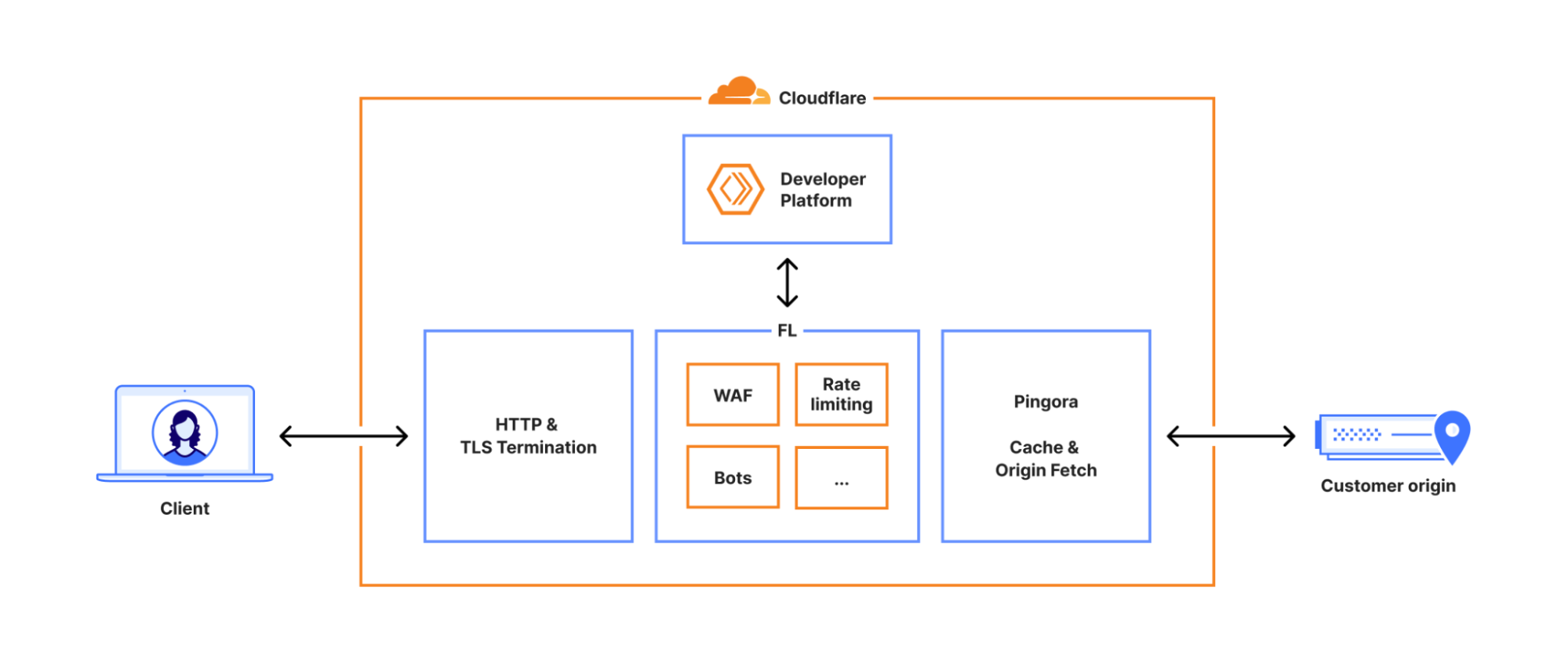
Apart from a few cyber-ermits on the margins, everyone noticed a Cloudflare outage yesterday (November 18th). They explained it in their post-mortem1 and, as always after the fact, it seems so simple...
- To improve their security, they revisited permissions in their database. Queries are no longer made by a shared account but by a dedicated user account for each system. Importantly, these user accounts implicitly have access to the
r0table. - The bot detection rule generation system has one of its queries that retrieves data from the
defaulttable, but without naming it on the assumption that it's the only table it has access to. Except that after the modification, it also retrieved data fromr0. - This extra data generated many duplicates that weren't filtered out in the detection rules and their number skyrocketed (from about sixty to over 200). The new configuration file containing all these lines was then sent to the bot detection systems.
- For optimization purposes, these systems allocate a fixed-size memory buffer to read this configuration. Too large to fit, the system couldn't load the file. The error generated wasn't caught by the code that tried to convert the error into configuration lines… and thus crashed.
- On Cloudflare's old proxies, the crash generated a systematically null bot score. Clients not using this score therefore didn't see a problem but for the others… the bot detection system blocked everything. On the new proxies, the crash was detected as an internal error and a
5xxcode was returned to visitors, blocking the corresponding traffic. - All Cloudflare services are hosted behind their own proxy and therefore also stopped working.
It took 20 minutes for the database update to crash the first flows. Cloudflare took two hours to determine that the blockage was due to the bot detector, and another hour to trace back to the configuration file and start deploying an older file. Two and a half hours later, the systems were back to normal. Very frankly, we can salute their performance (and thank them for their post-mortem).
The first lesson is that in computing, it's like in aviation. When a system crashes, it's rarely due to a single error but more often a cascade of small individual errors. They can all seem minor or even be justified individually, but put together, the cascade makes the vase overflow.
The other lesson is that by adding more blocking security, we end up getting what we paid for: access is blocked. In a way, the system behaved exactly as it was supposed to. Faced with each error, the system took the most secure path: no bot could get through the barriers.
Karpman strikes again
Taking a step back, we can see it as a geometry problem... Websites are victims, Cloudflare is the rescuer. Except the rescuer can make blunders, and in that case, it transforms (against its will) into an aggressor. To get out of the triangle and avoid this kind of problem, it would be more resilient for everyone to take care of their own security.
Most websites don't need these CDNs. All that cached content... the cache is all well and good, but when you think about it, they're just static sites placed in front of other static sites… Except you also need to put other proxies, load balancers, and various detectors in front that slow everything down2.
So we can then ask the legitimate question...
What's the point?
The Legitimate Question
For Cloudflare, beyond the revenue from billing the service, we can note that they are the TLS termination of all the traffic we've entrusted to them. In other words, cryptography stops at their door; they therefore see the traffic in clear text3.
Do It Yourself
As Lord wrote, this entire layer can absolve employees of their responsibilities. But for the rest, why would we need all of this?
At the arsouyes, we only have a static site containing only public information. No access control, no code interpretation, no vulnerability to hide behind a WAF4, no cache to slow down file transmission.
Especially since, as Lord writes, if we want to manage availability, we could do it ourselves. Redundant DNS servers, then redundant web servers, and load balancing via DNS records. And why not go further and exchange this redundancy between friends: each one redunds the others.
We could go further. Since our sites are just static content, anyone could crawl the content and produce a clone on their server. This redundancy would be proof that we support the original site's author. A much more concrete (and impactful) proof than a pseudo like on a pseudo social network.
Let's set aside the idea that the author didn't ask for a rescuer to help redund their site for them, and let's still pursue this idea to see where it can lead…
Why not automate everything? And if we could pin the sites we like and thus serve as a mirror automatically. We could even add a layer of public key cryptography to authenticate content and avoid being usurped by a scunner. And why not also handle addressing and do without DNS?
And boom, you have IPFS and other protocols of the kind...
Why redundancy?
But the question I'm interested in is not so much how to technically solve the problem (we just saw that IPFS offers a solution) but rather "why would we need to do it?"
I mean, let's say the datacenter hosting the arsouyes burns5, it would take no more than a day to rebuild everything (the longest time would be DNS propagation). Let's imagine worse, that the site is unreachable for a month. Let's even go two months for good measure. Will the world plunge into chaos because you no longer have access to our texts?
Since it's not a problem of availability, it might be a problem of preserving humanity's cultural heritage. The idea that disappearance would be permanent would worry you and justify implementing long-term preservation methods…
The work is a legacy to future generations.
I'm not sure all our articles truly deserve to be saved to this extent. I mean, we regularly clean house and no one ever comes to ask what happened to a disappeared article. Conversely, should we really burden humanity with saving our own texts?
Yet that's the mission Wayback Machine has set itself. As you might suspect, we're on it but not all our pages have been saved. I don't complain, if I wanted an archive of my own site, I would have made one. And if I haven't, it's because this problem doesn't worry me.
To take the reflection to its conclusion, I don't find websites suitable for transmission to future generations. Beyond technical backward compatibility issues, our sites are in constant mutation and contain many links to other sites, also in permanent mutation. To save them in their environment, one would need to capture the entire web each time it changes…
What about books then?
Unlike the web where it's very easy to publish, books impose a much slower pace. Between the idea and its publication, books require intermediate steps that don't exist for the web (e.g. printing on paper and binding), or that exist but are more expensive and/or longer.
Paradoxically, I find that this heaviness is their strength. If we want to bequeath something to future generations, with humility6 and sincerity7, the book is full of opportunities8.
Consistency. Our posts are about 1,700 words on average9. For a small 100-page book, you need between 20,000 and 30,000 words. That's 12 to 18 average-sized posts. If you aim for 400 pages, you need the equivalent of 47 to 70 posts.
At the risk of producing emptiness or an incoherent collection, the book's subject must be substantial enough to fill all those pages on its own.
Maturity. To treat a subject over the length of a book, you must master it in depth. If it's not always the case at the beginning of the project, it will end up becoming so. But careful, it's not enough to accumulate content to fill pages. You must be able to organize it to give it meaning. And that also means choosing what won't be in the book.
La perfection est atteinte, non pas lorsqu'il n'y a plus rien à ajouter, mais lorsqu'il n'y a plus rien à retirer.
Antoine de Saint-Exupéry
Writing a book is not about drawing an exhaustive map of the subject. It's much more than that. It's about telling the journeys that give meaning to the map.
Quality. Before publishing a book we want to bequeath to Humanity, we must verify it at all levels. There is the text; and its spelling, word choices, formulations, and transitions. There is also the para-text; with footnotes, references, citations, source codes10, illustrations and diagrams.
There is also the form. With all its typographic and layout choices. Making sure that the para-text is on the same spread as the text that references it11 so that the reader doesn't have to flip pages back and forth, or that source codes are not split by a page break.
And when we think we've reached the goal: print the book to read it and have beta-testers read it. Wait for their feedback and realize the errors that slipped through our nets and get back to work. Again. Because if it's easy to fix a blog post after the fact, it's much harder once the books are printed and sent to their readers.
Interest. Given the pitfalls to overcome, only ideas that motivate the author enough to pursue the adventure will survive the process. A sort of natural selection that discards ideas in the air to keep only those that make sense12.
And after
Once we reach the end of the road, we have the satisfaction of having produced an object worth the effort. And as a physical object, the book has several advantages.
First, it's a deeply human medium. Unlike an ebook or a website, you don't depend on computers; as long as you can read, you can enjoy the book. Conversely, AI robots only have access to digital works and as long as nobody digitizes the book, these plagiarism machines won't have access to it13.
Next, it's a deeply free medium. Even if the book in its material realization is covered by copyright, its content is free. Even if it's not under a Creative Commons license, you can use it freely in the sense of the Free Software Foundation:
- You can use the book for any purpose (including to level a piece of furniture),
- You can analyze it as much as you want to understand it,
- You can lend it to anyone you want so they can enjoy it (including to level their furniture),
- You can write your own books with your own thoughts and adaptations of the books you've read.
Finally, it's a deeply resilient medium. Each copy in circulation is an autonomous backup. No need for internet, no need for reading equipment, as long as you have one on your shelf, you can read it. As long as there remains one book in circulation, its content remains available to Humanity (and there are two at the BNF).