Backup de données chez OVH avec duplicity
Divulgâchage : Avec la quantité de données
grandissante des arsouyes, nous avons souhaité mettre en place un
système de sauvegarde incrémental utilisant le Public Cloud OVH. On va
utiliser un stockage dans le cloud et le logiciel duplicity
pour y envoyer nos données. Le tout de manière incrémentale.
Article Obsolète : Depuis le 24 mars 2020, et le passage de la version 2 à la version 3 de l’API Keystone par OVH, cet article est obsolète. Veuillez consulter l’article « Mettre en place une sauvegarde chez OVH avec Duplicity » pour la version à jour.
Ayant notre propre serveur dans notre garage, nous nous sommes posé la question de la sauvegarde. Nous avons des disques dur en RAID, ce n’est pas vraiment les crash disque que nous craignons plus qu’un cryptolocker ou un incendie.

Tout copier sur un disque dur externe une fois par mois, le débrancher et le stocker hors de chez nous, c’est un peu has been. On va donc vous expliquer les moyens que nous avons mis en place afin de stocker de manière efficace et automatique nos données.
Choix de la méthode et de l’outil
Tout d’abord, on veut quoi exactement ? Sauvegarder ses données ? Oui, mais quoi d’autre ? Il faut se poser les questions pertinentes afin de déterminer exactement les besoins et en sortir les outils adéquats.
Qu’est ce qu’on sauvegarde?
Pour le moment, uniquement des fichiers. Le plus gros de la sauvegarde sera constitué de photos de famille en JPEG, donc des données déjà compressées, qu’il est inutile de chercher à compresser plus. Le reste étant anecdotique en volume par rapport aux photos et vidéos, car il s’agit surtout de fichiers texte.

Pour résumer, plusieurs giga de données, pas forcément compressibles.
Et on fait quoi maintenant de cette information ?
Maintenant que l’on sait que l’on a plusieurs giga de données à sauvegarder, il ne nous viendrait pas à l’idée de les envoyer toutes les nuits entièrement sur le serveur externe de sauvegarde. Tout d’abord, parce que ça génèrerait un trafic monstre pour pas grand-chose, et également parce que certains opérateurs font payer le trafic entrant…
La solution est donc de faire une sauvegarde incrémentale de nos données. C’est à dire qu’au lieu de les envoyer bêtement toutes les nuits entièrement sur le serveur de backup, on va faire un diff, et n’envoyer que ce qui a changé. Cette sauvegarde incrémentale est tout de même configurée de manière intelligente. C’est à dire qu’il est programmé régulièrement des sauvegardes complètes, pour que le jour où l’on souhaite récupérer nos données, la récupération ne soit pas trop longue.
Et je me débrouille comment avec mes fichiers à envoyer ?
Evidemment, cela serait un gaspillage de place que de copier tous les fichiers à sauvegarder à un endroit, afin de les envoyer ensuite sur le serveur distant. Pour cela, une solution est de créer un répertoire contenant ce que l’on souhaite backuper, mais au lieu d’y coller ce qu’on veut sauvegarder, on se contentera de faire des liens symboliques.
Bien sûr, pour cela, il faut que l’outil de backup gère les liens symboliques, c’est à dire qu’il copie les fichiers correspondants, et non juste les liens, ce qui avouons-le, ne serait pas très utile.
Et mes sauvegardes, elles seront conservées combien de temps ?
Tout dépendra de ce que l’on configurera dans le logiciel. Pour cela, il faut donc un logiciel qui puisse gérer lui-même l’effacement des données trop vieilles. Evidemment, comme nous avons choisi de faire une sauvegarde incrémentale, la quantité de données sur le serveur ne devrait pas exploser, mais comme nous souhaitons quand même faire quelques sauvegardes complètes, on doit s’assurer de ne pas garder des backups trop vieux pour ne pas surcharger inutilement serveur.
Et encore quelque chose ?
Ensuite, le chiffrement des données serait un plus. En cas de compromission du serveur de backup, on pourra ainsi s’assurer que nos photos perso ou nos documents administratifs ne se promènent pas dans la nature.
Au final
À la vue de notre cahier des charges, nous avons opté pour duplicity, parce qu’il regroupait ce dont on avait besoin, qu’il existe de la documentation en ligne, et qu’il est dans les packages Ubuntu, OS de notre NAS.
Choix du serveur de stockage externe
Dans le monde de la sauvegarde dans le cloud, il existe le stockage à froid et le stockage classique dans le cloud. La différence principale entre ces deux types de stockage est qu’il faut un délai pour l’extraction des données dans un stockage à froid.

Cela pouvant poser quelques problèmes car notre solution de sauvegarde incrémentale nécessite de pouvoir accéder rapidement aux données afin de vérifier si elles ont été modifiées ou non… Nous avons donc choisi un stockage classique dans le cloud.
Nous avons choisi la solution Object Storage de OVH . Tout d’abord, parce que ce n’est pas très cher, et en plus, car nous avons déjà un compte chez eux pour certains de nos services, et que ça évite donc de multiplier les comptes clients…
La solution Object Storage ne permet de payer qu’au Go stocké (0.01€ H.T./mois/Go) et au Go sortant (0.01€HT/go)… Autant dire qu’il faut avoir quand même beaucoup de données avant que le coût soit rédhibitoire.
Mise en place
Création du conteneur de stockage chez OVH
Pour commander un Public Cloud, je vous laisse faire. Sachez juste qu’il s’agit des offres professionnelles et que du coup, ils vont vous demander des informations et des copies de pièces d’identité.
Une fois que l’administratif a suivi son cours et que vous avez enfin
accès à votre public cloud
, il suffit de vous connecter sur le
manager d’OVH.
Ensuite, dans l’onglet Cloud, dans la partie Serveurs, vous avez accès à votre serveur. Il faut créer un conteneur de stockage.
Pour cela, rien de plus simple, il suffit de cliquer sur créer un conteneur.

On vous demandera quel Datacenter, puis le type de conteneur, et enfin de le nommer.
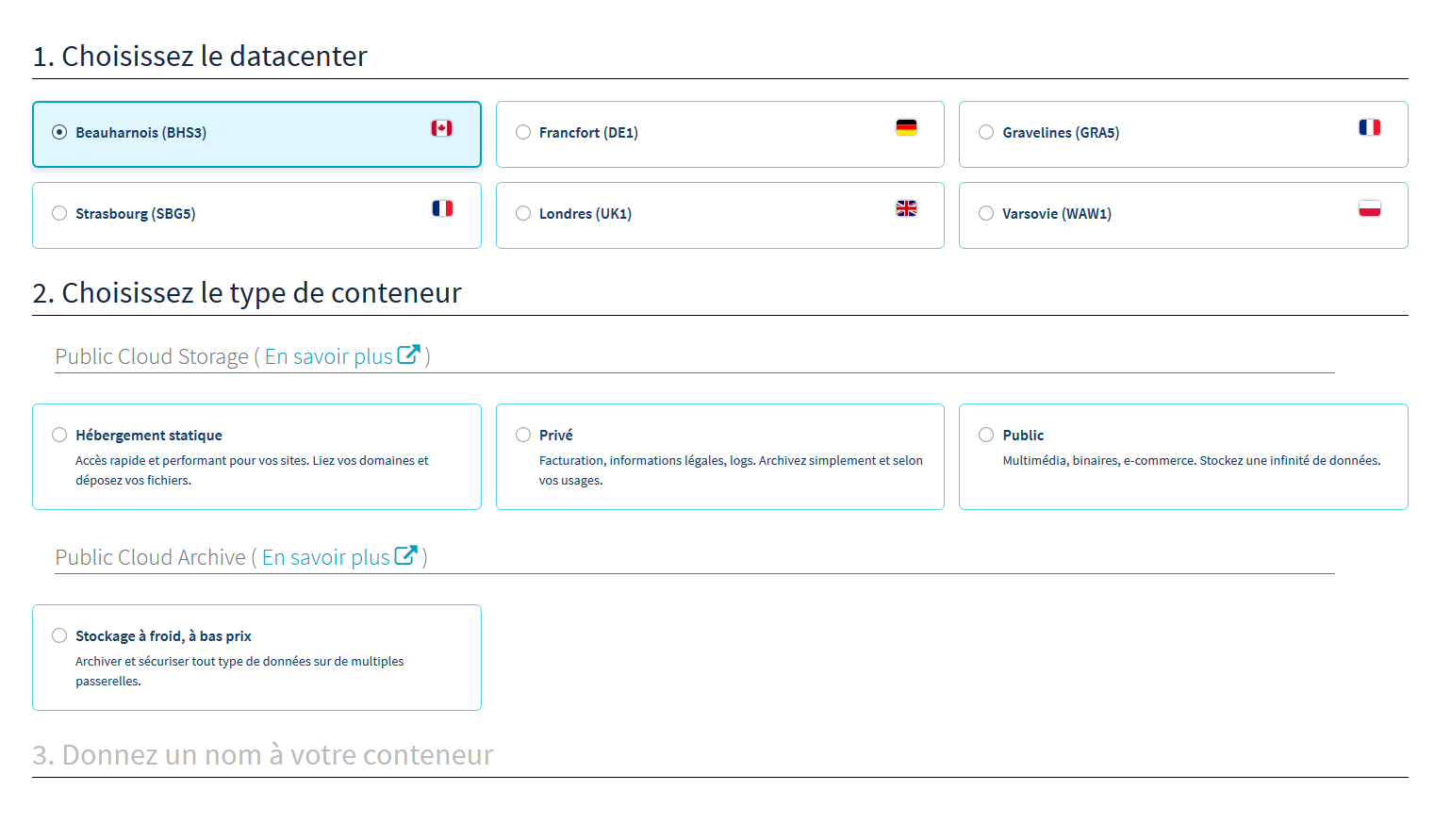
Vous pouvez choisir le datacenter que vous souhaitez, mais je vous conseille de réfléchir et de prendre le plus près de chez vous.
Pour ce qui est du type de conteneur, vu que l’on cherche juste à sauvegarder des données privées, un conteneur privé sera plus pertinent. Enfin, donnez le nom que vous souhaitez à votre conteneur.
De retour dans Stockage, votre conteneur doit apparaître.
On va ensuite créer un client OpenStack, qui va nous servir pour l’envoi des données dans le conteneur. Pour cela, on va dans Gestion Technique / Openstack Users.
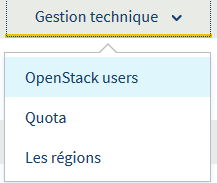
Il suffit ensuite de faire Ajouter un utilisateur et de lui donner un nom.
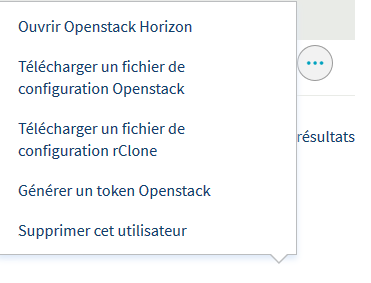
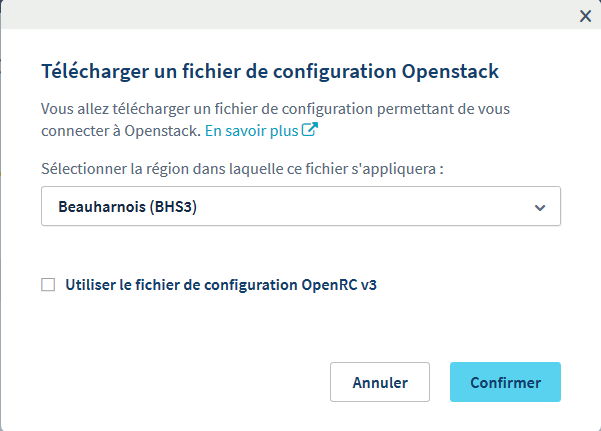
Enfin, on va télécharger le fichier de configuration OpenStack, afin de récupérer les données utiles plus tard pour l’envoi des données. Pour cela, on clique sur les trois petits points à droite de l’utilisateur, puis sur Télécharger un fichier de configuration OpenStack.
Sélectionnez votre Datacenter, cochez la case et c’est parti, vous récupérez un fichier openrc.sh, dans lequel vous trouverez les infos utiles plus tard pour la connexion.
Installation de duplicity
Pour installer duplicity sur notre Ubuntu (on en profite
pour mettre les dépôts à jour au passage)
apt-get update
apt-get install duplicityOn utilise ensuite pip pour installer les modules requis
par duplicity pour l’authentification Openstack
(python-keystoneclient) et le stockage
(python-swiftclient).
pip install python-swiftclient python-keystoneclientPréparation du chiffrement
Pour cela, nous allons générer des clefs. J’ai choisi personnellement d’utiliser la même clef pour chiffrer et pour signer.
gpg --full-gen-keyEt on se laisse guider pour la génération. Pour la taille des clefs, l’ANSSI donne les règles suivantes :
RègleFact-1 La taille minimale du module est de 2048 bits, pour une utilisation ne devant pas dépasser l’année 2030.
RègleFact-2 Pour une utilisation au-delà de 2030, la taille minimale du module est de 3072 bits.
En suivant les recommandations de la doc de ubuntu, on a choisi 4096 bits. On affiche ensuite les clefs avec la commande suivante :
gpg --list-keysNe pas hésiter à exporter ses clefs et les sauvegarder, car si demain, votre NAS flanche et que vos clefs sont uniquement dessus, vous ne pourrez pas récupérer vos sauvegardes sur le serveur de backup.
Le backup en lui-même
Nous avons maintenant tout ce qu’il nous faut pour le backup. Comme on dit, Y a plus qu’a.
Pour cela, on va faire un script qui va tout faire pour nous…
C’est pour cela qu’on a récupéré plus tôt le script openrc.sh, c’est parce qu’il contient des données qui vont nous être utiles.
Dans ce script, on récupère les variables suivantes :
SWIFT_USERNAME
SWIFT_PASSWORD
SWIFT_AUTHURL
SWIFT_AUTHVERSION
SWIFT_TENANTNAME
SWIFT_REGIONNAMEIl nous faudra ensuite les données suivantes :
- key id : l’id de la clef utilisée. D’après la RFC 4880,
l’id de l’exposant public d’une clef RSA est constitué de ses 64
derniers bits. Pour simplifier, lorsque vous affichez vos clefs RSA avec
gpg --list-keys, il s’agit des 16 derniers caractères. - src dir : Il s’agit du répertoire où se situent les données à sauvegarder.
- dest : Il s’agit de l’endroit où doivent être sauvegardé les données. C’est à dire l’adresse du conteneur créé précédemment. Notre conteneur s’appelant sauvegardes, l’adresse est swift://sauvegardes.
- passphrase : c’est la phrase secrète correspondant à votre clef.
On peut tout mettre ensemble dans un script pour faciliter l’utilisation :
#!/bin/bash
key=<key id>
src=<src dir>
dest=<dest>
# OpenStack
export SWIFT_USERNAME=<SWIFT_USERNAME>
export SWIFT_PASSWORD=<SWIFT_PASSWORD>
export SWIFT_AUTHURL=<SWIFT_AUTHURL>
export SWIFT_AUTHVERSION=<SWIFT_AUTHVERSION>
export SWIFT_TENANTNAME=<SWIFT_TENANTNAME>
export SWIFT_REGIONNAME=<SWIFT_REGIONNAME>
# GnuPG
export PASSPHRASE=<passphrase>
duplicity --full-if-older-than 1M \
--copy-links \
--encrypt-key "$key" \
--sign-key "$key" \
--num-retries 3 \
--asynchronous-upload \
--cf-backend swift \
--volsize 100 \
"${src}" "${dest}"
duplicity remove-older-than 2M --force "${dest}"
unset \
SWIFT_USERNAME \
SWIFT_PASSWORD \
SWIFT_AUTHURL \
SWIFT_AUTHVERSION \
SWIFT_TENANTNAME \
SWIFT_REGIONNAME \
PASSPHRASELes options sélectionnées pour duplicity sont les
suivantes:
full-if-older-than 1M: on demande àduplicityde refaire une sauvegarde complète si cela fait plus d’un mois que la dernière a été faite,copy-links: demande àduplicityde copier les fichiers pointés par les liens symboliques et non les liens en eux même,encrypt-key: la clef de chiffrement,sign-key: la clef de signature,num-retries: nombre de réessaies après erreurs,asynchronous-upload: permet àduplicityde préparer l’envoi suivant pendant qu’il envoi le fichier en cours,cf-backend: le système de sauvegarde, ici swift,volsize: réduit la taille des paquets envoyés parduplicity.
La seconde ligne duplicity permet de supprimer les
backups trop vieux (2 mois).
Récupération
Nous avons également fait un petit script afin de récupérer les
données, en reprenant les mêmes informations. Seule modification,
puisque on récupère, la variable src contient maintenant
l’adresse du conteneur.
#!/bin/bash
key=<key id>
src=<src>
dest="/tmp" #répertoire où l'on va récupérer la sauvegarde
# OpenStack
export SWIFT_USERNAME=<SWIFT_USERNAME>
export SWIFT_PASSWORD=<SWIFT_PASSWORD>
export SWIFT_AUTHURL=<SWIFT_AUTHURL>
export SWIFT_AUTHVERSION=<SWIFT_AUTHVERSION>
export SWIFT_TENANTNAME=<SWIFT_TENANTNAME>
export SWIFT_REGIONNAME=<SWIFT_REGIONNAME>
duplicity --verbosity notice \
--encrypt-key "$key" \
--sign-key "$key" \
--num-retries 3 \
--cf-backend swift \
"$src" "$dest" 2> /dev/nullPour plus de détails sur la récupération, c’est par là.
Automatisation
Maintenant que l’on a le lieu de stockage, l’outil et le script, on va tout automatiser pour que ça se fasse toutes les nuits.
Pour cela, rien de plus simple : crontab -e Et on ajoute
une ligne correspondant au script à lancer. Ici, on lance le script
toutes les nuits à minuit.
0 0 * * * <chemin du script>