Déploiement continu et répertoire web dynamique
Divulgâchage : Lorsqu’on développe des applications web, on aime généralement bien pouvoir déployer facilement des variantes pour faire des tests (et éventuellement les fusionner ensuite). Et se pose le problème de leur hébergement et de leurs adresses web… On va utiliser un serveur DNS pour faire pointer les sous-domaines vers une seule machine, un certificat TLS spécifique pour gérer ces noms, un VirtualDocumentRoot côté apache pour rediriger les requêtes vers le répertoire correspondant et la CI de gitlab pour déployer les fichiers en fonction du nom de la branche.
Que ce soit pour le site des arsouyes ou pour freedomnia, on a mis en place un serveur de pré production. Lorsqu’on ajoute une fonctionnalité ou qu’on rédige un article, on préfère d’abord le déployer là bas avant de le pousser en production (ça évite quelques ratés).
Pour les cas un peu plus longs, l’idéal est de passer par une branche dédiée. Tant qu’elles ne sont pas terminées, la fonctionnalité ou la rédaction sont préparées dans leur coin, sans interférer avec la branche principale sur laquelle on peut quand même faire des modifications qu’on pourra vérifier en pré-production puis pousser en production.
Autant déployer manuellement quelques environnement statiques, c’est faisable (e.g. « production » pour la version définitive, « staging » pour la pré-production et éventuellement « testing » pour les tests). Autant ça devient vite pénible si on veut le faire pour chaque petite branche qu’on crée au fil de l’eau.
Et pourtant, ce serait tellement pratique de pouvoir visualiser chacune d’entre elle…

Heureusement, si votre application ne nécessite que de copier son contenu dans le répertoire d’un serveur web, vous allez pouvoir automatiser la création de ces environnements. Sinon, avec de la chance, vous allez pouvoir adapter la méthode qu’on va vous montrer ici.
Préparer le terrain
Vous vous en doutez, pour qu’une application web fonctionne, il ne suffit pas de configurer un serveur web, il faut aussi que le DNS associe son nom à son IP et que les certificats TLS soient créés pour sécuriser les flux.
Configuration DNS
Une fois les machines installées et branchées au réseau, je préfère toujours commencer par la configuration DNS. Comme on va utiliser des noms d’hôtes pour les connexions au serveur web, ça évitera de devoir les renseigner à la main dans les en-têtes. C’est possible mais c’est bien plus pratique de laisser le navigateur utiliser l’URL directement.
On va donc choisir un domaine (i.e.
grav.arsouyes.org) et configurer notre serveur DNS pour que
lui, ainsi que tous ses sous-domaines, pointent vers la même adresse IP
(celle du serveur web).
Avec pfSense. Il faut se rendre dans le menu « Services / DNS Resolver » puis ajouter une configuration spécifique dans le champ de texte « Custom options » :
server:
local-zone: "grav.arsouyes.org" redirect
local-data: "grav.arsouyes.org 86400 IN A 192.168.0.124"Ces lignes disent au serveur DNS que le domaine
grav.arsouyes.org, ainsi que tous ses sous-domaines,
doivent pointer vers l’adresse 192.168.0.124 (cette
information ayant une durée de vie de 86400 secondes, soit une
journée).

Avec unbound. Comme c’est le serveur DNS embarqué par pfSense, vous pouvez utiliser la même technique.
Avec bind. Si vous utilisez plutôt un serveur DNS
bind9, vous pouvez insérer, dans votre fichier de zone, une
ligne de ce genre :
*.grav.arsouyes.org IN A 192.168.0.124Sous windows. Si vous avez un serveur DNS sous
windows (i.g. intégré à votre AD), vous pouvez aussi y ajouter
un « wildcard DNS », pour ça, ajoutez une entrée comme vous le feriez
habituellement (A ou CNAME) mais renseignez *.grav (ou
seulement * suivant votre cas) comme nom.
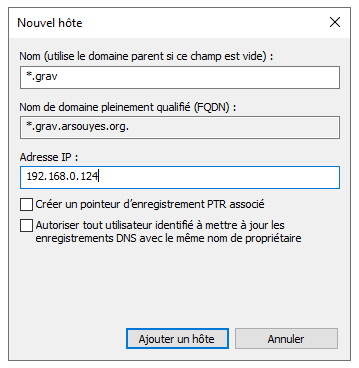
Après une purge éventuelle des caches DNS de vos clients, à partir
d’ici, toute connexion réseau vers un sous-domaine (e.g.
test.grav.arsouyes.org) devrait aboutir vers votre serveur
web.
Certificat TLS
Préférence personnelle, je m’occupe ensuite des certificats pour pouvoir configurer directement mon serveur web en HTTPS. Techniquement, on pourrait d’abord tester sans TLS et ne s’y mettre qu’ensuite (vous pourriez donc passer à la section suivante).
Le certificat qu’on va générer est un peu différent des autres car on ne va pas pouvoir y écrire, à l’avance, tous les sous-domaines pour lesquels il va servir puisqu’on veut pouvoir choisir nos noms après. Heureusement, le format X509 (celui des certificats) a déjà ce qu’il faut pour ajouter un nom alternatif générique.
Pour la suite, je ne vous montre que la subtilité par rapport à l’habituel. Si vous ne savez pas comment générer des certificats, vous pouvez lire cet article avec les étapes habituelles.
Si vous utilisez XCA, dans l’onglet « Extension », il faut modifier
le « X509v3 Subject Alternative Name » (cliquez sur le bouton modifier à
sa droite) et ajouter l’entrée DNS générique
(*.grav.arsouyes.org, à adapter chez vous).
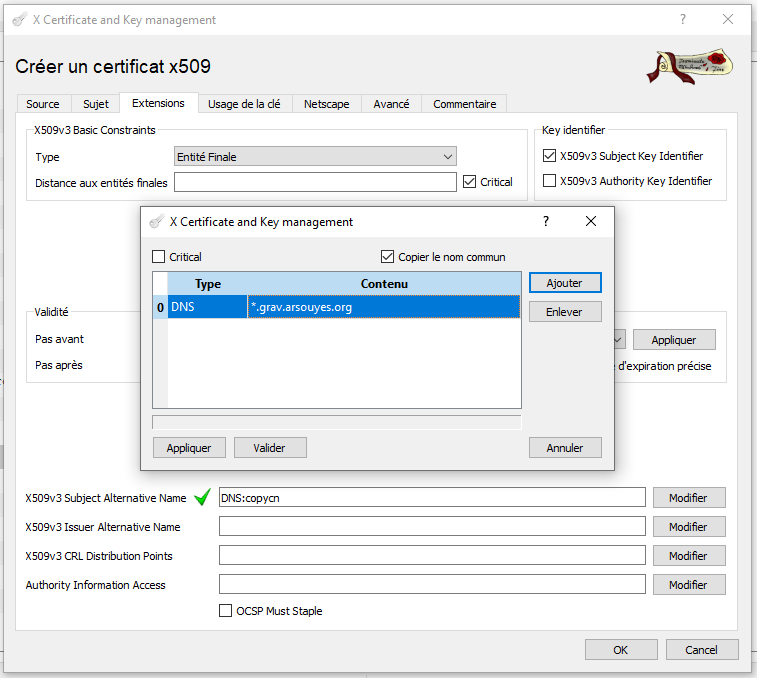
Vous pouvez alors compléter les autres paramètres comme d’habitude et enfin exporter les fichiers :
- Le certificat, qu’on nommera
grav.arsouyes.org.crtdans la suite (mais vous pouvez lui donner un autre nom), - La clé, qu’on nommera
grav.arsouyes.org.keydans la suite (idem, soyez créatifs).
Configuration web
Comme je vous le disais, on voudrait qu’à chaque nom de domaine d’une
requête, corresponde un répertoire différent dans le système. Ça tombe
bien, apache2 a justement une directive faite rien que pour ça,
VirtualDocumentRoot qu’on va donc utiliser.
C’est possible aussi avec d’autres serveurs web, comme nginx mais comme nous n’en avons pas sous la main, on a pas pu tester les informations sur le web. Et puis je trouve qu’apache à un petit côté vieille école que j’aime bien (et non, je suis pas réac’).

La base, en http
Pour ça, il faut d’abord activer le module
mod_vhost_alias (c’est lui qui fourni cette directive).
Sous ubuntu et cie., cette ligne fait tout le nécessaire :
sudo a2enmod vhost_aliasLa commande vous dit qu’il faut maintenant recharger apache2 pour prendre en compte le changement mais comme on va de toutes façon ajouter un vhost ensuite et qu’on devra le recharcher aussi à ce moment là, on peut reporter cette opération à ce moment là.
On crée ensuite le fichier de configuration du vhost, sous ubuntu
dans /etc/apache2/site-available/grav.arsouyes.org.conf
avec le contenu suivant :
- ServerName : configure le nom de domaine «principal» de ce vhost,
- ServerAlias : configure des noms «alternatifs» qu’on peut aussi utiliser, en y mettant un astérisk, on dit à apache que les sous-domaines sont aussi gérés par ce vhost.
- VirtualDocumentRoot : configure le répertoire
racine du vhost, mais autorise des variables, ici,
%0sera remplacé par le nom de domaine complet utilisé dans la requête. Pour les détails, vous pouvez lire la documentation officielle, elle est plutôt bien rédigée. - Les autres directives sont on ne peut plus classiques (j’ai volontairement omis ce qui n’est pas essentiel, à vous d’ajouter vos spécificités).
<VirtualHost *:80>
ServerAdmin hello@arsouyes.org
ServerName grav.arsouyes.org
ServerAlias *.grav.arsouyes.org
VirtualDocumentRoot /var/www/%0
<Directory /var/www/>
Require all granted
</Directory>
</VirtualHost>Il est donc nécessaire que chaque nom de domaine qu’on compte utilisé ait un répertoire correspondant. Si on voulait créer les trois environnements dont on parlait en intro, on ferait quelque chose de ce genre :
sudo mkdir /var/www/production.grav.arsouyes.org
sudo mkdir /var/www/staging.grav.arsouyes.org
sudo mkdir /var/www/testing.grav.arsouyes.orgLa création de ces répertoire ne sera par contre pas nécessaire si, comme on vous le montre à la fin, vous passez par l’intégration continue pour déployer automatiquement vos branches dans ces répertoires.
On peut alors activer le vhost et recharger la configuration d’apache avec ces deux commandes :
sudo a2ensite grav.arsouyes.org.conf
sudo systemctl reload apache2Si un visiteur entre un sous-domaine pour lequel le répertoire n’existe pas, apache retournera une erreur 404 générique, évitez-donc de mettre ce genre de configuration accessible depuis le grand Internet.
La sécurité, en HTTPS
Une fois que vous avez vos certificats particuliers (avec le nom de domaine générique) et que votre vhost HTTP fonctionne, techniquement, la configuration HTTP est la même que d’habitude.
On commence par déployer les deux fichiers précédents sur le serveur web :
- Le certificat, devrait être placé dans le
répertoire
/etc/ssl/certs, - La clé, devrait être placé dans le répertoire
/etc/ssl/private.
L’utilisation de ces deux répertoires n’est pas obligatoire mais a l’avantage de suivre les habitudes. Ils sont donc déjà configurés avec les droits d’accès qui vont bien, et un autre admin qui passe après vous retrouvera vos petits plus facilement.
Si ça n’est pas déjà le cas, il est nécessaire d’activer le module
mod_ssl (qui, bien que son nom l’indique mal, fait bien tu
TLS).
sudo a2enmod sslPour la configuration du vhost, pour aller au plus simple, on va
ajouter ce contenu au fichier de configuration précédent (il aura donc
deux directives VirtualHost). C’est le même qu’en HTTP
auxquel on a ajouté les directives SSL/TLS classiques.
<VirtualHost *:443>
ServerAdmin hello@arsouyes.org
ServerName grav.arsouyes.org
ServerAlias *.grav.arsouyes.org
VirtualDocumentRoot /var/www/%0
SSLEngine on
SSLCertificateFile /etc/ssl/certs/grav.arsouyes.org.crt
SSLCertificateKeyFile /etc/ssl/private/grav.arsouyes.org.pem
<Directory /var/www/>
Require all granted
</Directory>
</VirtualHost>Si vous préférez n’avoir qu’un seul vhost par fichier, vous pouvez mettre le contenu précédent dans un deuxième fichier (i.e.
grav.arsouyes.org-ssl.conf, dans/etc/apache2/site-available) mais n’oubliez pas qu’il faudra également l’activer d’unsudo a2ensite grav.arsouyes.org-ssl.
Il ne reste alors plus qu’à recharger la configuration d’apache pour qu’il prenne en compte ces changements :
sudo systemctl reload apache2Et voilà, vos environnements sont non seulement disponible, mais
aussi accessible en https.
Déploiement continu
Techniquement, on pourrait s’arrêter ici, il suffit de créer un
répertoire (avec un nom finissant par .grav.arsouyes.org)
et d’y mettre du contenu pour qu’il soit accessible via un navigateur.
Mais comme je vous parlait de branches en introduction, autant aller au
bout de l’idée…
Pour ces opérations, je vais me baser sur GitLab et surtout, ses runners et son intégration continue.
Le runner
Comme le but, c’est de faire quelque chose de simple, installons un runner directement sur la machine qui sert de serveur web.
Si vos applications sont tatillonnes sur les droits d’accès des fichiers, il est peut être nécessaire de changer l’identité utilisateur utilisée par le runner.
Pour freedomnia, nous utilisions un CMS statique, jekyll, qui construisaitt le site statique. Une fois déployé, apache n’a besoin que d’un accès en lecture et comme le runner crée les répertoires en
775et les fichiers en664, c’est largement suffisant et nous n’avons rien eu à faire pour ce serveur.Par contre, pour le site des arsouyes, on utilise grav qui a besoin que certains répertoires soient « sa » propriété (en fait, celle de
www-data) pour son cache et autres particularités. Plutôt que de donner au runner des droits sudo pour changer le propriétaire des fichiers qu’il crée, on peut aussi le faire fonctionner directement en tant quewww-data.
Si vous voulez que le runner utilise une autre identité, il faut
désinstaller le service puis le réinstaller avec de nouveaux paramètres,
pour ça, vous pouvez adapter les deux commandes suivantes (ici, on
configure avec l’utilisateur www-data) :
gitlab-runner uninstall
gitlab-runner install --working-directory /var/www --user www-dataA partir d’ici, vous pouvez enregistrer votre runner comme d’habitude mais définissez son mode d’exécution (son executor) à « shell ». Ce sera plus pratique pour copier des fichiers et lancer les commandes sur le serveur.
Le mode « ssh » n’est pas vraiment adapté à notre cas de figure. D’un côté parce qu’il va imposer de stocker des identifiants pour qu’il puisse se connecter au serveur web (ce qui n’est pas super) et parce qu’il est vulnérable à un MITM (il ne vérifie pas la clé du serveur).
De même, certains autres modes sont spécifiquement conçus pour du déploiement automatique (i.e. kubernetes) mais à ce compte là, nos étapes précédentes étaient inutiles puisque vous avez déjà une plateforme plus complexe.
L’intégration continue
Maintenant qu’on a un agent pour exécuter nos commandes, il n’y a
plus qu’à les écrire dans le fichier de configuration de l’intégration
continue de gitlab (le fameux .gitlab-ci.yml).
Pour déterminer le nom de la branche, le mieux, c’est d’utiliser la
variable CI_COMMIT_REF_SLUG car non seulement elle est
définie lors des merge requests (ce qui n’est pas le cas de
CI_COMMIT_BRANCH) mais en plus, elle est adaptée pour
fonctionner comme nom DNS (contrairement à
CI_COMMIT_REF_NAME, les non alphanumériques sont remplacés
des -).
Comme je suis du genre à simplifier les scripts, je commence par définir quelques variables pratiques :
VHOST_DIRECTORY: que j’utiliserai dans mes commandes, ça les rendra moins longues,GIT_STRATEGY: que je met ànonecar je n’ai pas besoin que le runner récupère le code dans son répertoire de travail,GIT: qui me permet de stocker le chemin vers la commande et évite de le retaper à chaque fois ensuite.
variables:
VHOST_DIRECTORY : /var/www/${CI_COMMIT_REF_SLUG}.grav.arsouyes.org
GIT_STRATEGY: none
GIT: /usr/bin/gitOn peut alors définir une tâche pour déployer nos environnements pour chaque branche :
- La directive
onlypermet de restreindre ces tâches aux branches, - La directive
environmentpermet de dire à gitlab que nous définissons un environnement particulier en lui fournissant un nom (directivename), une adresse (url) et, on va y revenir, une action lors de la suppression (on_stop), - Enfin, la directive
scriptdéfini les commandes à lancer pour déployer (dans notre cas, ungit clonela première fois puis desgit fetchpour mettre à jour à la bonne version).
Si votre application se déploie autrement, vous pourrez adapter cette tâche à vos contraintes, les deux seuls points importants ici sont a) utiliser
CI_COMMIT_REF_SLUGpour le nom de domaine et le répertoire et b) la directiveenvironmentpour déclarer votre environnement dans la CI.
deployement:
stage: deploy
only:
- branches
environment:
name: $CI_COMMIT_REF_NAME
url: https://${CI_COMMIT_REF_SLUG}.grav.arsouyes.org
on_stop: destroy
script:
- >
if [ ! -d $VHOST_DIRECTORY ] ; then
$GIT clone \
--branch $CI_COMMIT_REF_NAME \
$REPOSITORY_SSH \
$VHOST_DIRECTORY ;
fi
- cd $VHOST_DIRECTORY && $GIT fetch $CI_COMMIT_SHAAvec cette tâche, dès que l’intégration continue sera lancée sur un
commit (pour une branche ou un merge request), on mettra à jours le
répertoire correspondant pour contenir l’application dans cette version
spécifique. De son côté, la directive environment permet à
GitLab de prendre en compte qu’une application existe pour cette branche
et qu’il peut nous l’afficher à divers endroits de l’interface.
Pour terminer, on va définir la tâche destroy dont on a
fourni le nom dans la tâche précédente (pour la directive
on_stop).
Il s’agit d’une tâche spéciale dont le but est de supprimer l’environnement déployé et qui sera automatiquement appelée par GitLab lorsque l’environnement sera supprimé. Que ce soit parce qu’on a cliqué sur le bouton stop dans l’interface, ou parce que la branche a été supprimée.
- stage et only : doivent prendre la même valeur que la tâche qui crée l’environnement (sinon, ça peut ne plus marcher),
- environment : doit avoir le même nom, ne pas avoir
d’url (car elle n’est plus sensé être valide une fois l’environnement
supprimé) et la directive
actionqui vautstop. - script : un simple
rmfera l’affaire pour nous, mais on peut imaginer plus complexes suivant les cas, - when : doit absolument contenir
manual(en plus d’autres détails que vous auriez dans la tâche qui crée l’environnement).
destroy:
stage: deploy
only:
- branches
environment:
name: $CI_COMMIT_REF_NAME
action: stop
script:
- rm -rf $VHOST_DIRECTORY
when: manualCe n’est pas vraiment documenté mais
when: manualest nécessaire car sans elle, le runner (via la CI) va systématiquement l’exécuter pour chaque commit, et donc supprimer l’environnement à chaque fois aussi…
Avec cette seconde tâche, GitLab sait comment supprimer l’environnement et le fera automatiquement lorsqu’il ne sera plus nécessaire : si une tâche suivante échoue ou si la branche est supprimée.
Et après
Même si cet article est assez long, rétrospectivement, les étapes sont en fait plutôt simples voir classiques :
- Une ligne de configuration DNS (bon, trois dans le cas de pfSense),
- Une ligne de configuration TLS (extension SAN pour un domaine générique),
- Une ligne de configuration apache (le VirtualDocumentRoot, deux si on compte http et https),
- Un runner spécifique et des scripts de déploiement dans la CI (qu’on peut réutiliser d’un projet à l’autre).
Et pour si peux d’efforts, on peut maintenant abuser des branches et donc adopter une organisation de type « git flow » (et ses variantes où le développement d’une fonctionnalité doit passer par des branches spécifiques, la fameuse « feature branch »).
Ça peut paraître exagéré pour un site statique ou un CMS classique mais c’est en fait très pratique pour tester toutes nos idées. On peut donc partir dans n’importe quelle direction, voir ce que ça donne au fur et à mesure (sans rien toucher à la branche principale). Si c’est une bonne idée, on fusionne et vous en profitez, sinon, on supprime la branche et vous n’aurez rien vu.