Fonctions de hachage : les sommes de contrôle
 Available in english
Available in english- 20 novembre 2019
Divulgâchage : Utilisées pour vérifier l’intégrité des données, les fonctions de hachage sont partout. Aujourd’hui, nous vous présentons les sommes de contrôles, les plus faciles d’entre elles. Le principe est simple, puisque toute donnée est une suite de 0 et de 1, c’est donc un nombre qu’on peut projeter dans un ensemble plus petit. Dans l’idéal, une modification de la donnée l’enverra ailleurs et on verra la différence.
Dans un précédent article sur les infrastructures à clés publiques, j’avais abordé brièvement les fonctions de hachage, mais sans m’y attarder. Je me suis rendu compte, depuis, qu’elles sont plutôt méconnues. Et c’est bien dommage parce que même si on ne s’en rend pas compte, on s’en sert tout le temps.
Avant d’aborder leur version cryptographique dont il était question et qu’on abordera dans le prochain article, j’aimerais prendre un peu de temps pour vous présenter leurs ancêtres : les sommes de contrôles (checksum pour les anglophones). Bien plus simples, elles en possèdent déjà les caractéristiques fondamentales.

Tout part d’un besoin simple simple et plutôt commun en (sécurité) informatique :
Comment vérifier qu’une donnée a été transmise sans être altérée ?
Que ce soit la transmission d’un paquet via un réseau, le stockage de fichiers importants ou la copie d’un scellé. Comment s’assurer qu’il n’y a pas eu de problème et que la donnée reçue est bien conforme à l’originale ?
Bits de parité global
Commençons par la méthode la plus rudimentaire : compter le nombres
de bits qui valent
,
si ce nombre est pair, on ajoute un
,
s’il est impaire, on ajoute un
.
Mathématiquement, c’est faire un ou exclusif de tous les bits
du message. On l’écrit XOR dans le texte (pour eXclusive
OR) ,
en math et ^ en programmation.
| Donnée | |
|---|---|
| 00 | 0 |
| 01 | 1 |
| 10 | 1 |
| 11 | 0 |
| 011010011100110101 | 0 |
En termes de projection, ça permet de tout réduire à deux valeurs possibles : 0 ou 1. Un peu radical comme hachage mais si un seul bit change dans la donnée, la parité va changer aussi et on pourra détecter cette erreur 🎉.
Par contre, et c’est ici que c’est un peu limité, si deux bits changent, on ne le détectera plus 😥.
Bits de parité sur les mots
Pour aller plus loin, on peut découper le message en passages de même longueur (qu’on appelle des mots) et leur ajouter à chacun, leur bit de parité. On peut alors détecter plusieurs erreurs (tant qu’elles apparaissent dans des mots différents).
Pour de vrai, en ASCII. Jadis, chaque caractère était codé avec 7 bits. On pouvait alors en coder 128, ce qui était jugé largement suffisant à l’époque. Le 8ème bit, car on gérait déjà les données par paquets de 8 bits, pouvait être utilisé pour la parité et ainsi détecter les erreurs de transmission.
| Lettre | ASCII 7bits | parité | ASCII 8bits |
|---|---|---|---|
| B | 1000010 |
2 | 01000010 |
| o | 1101111 |
6 | 01101111 |
| n | 1101110 |
5 | 11101110 |
| j | 1101010 |
4 | 01101010 |
| o | 1101111 |
6 | 01101111 |
| u | 1110101 |
5 | 11110101 |
| r | 1110010 |
4 | 01110010 |
Le message Bonjour, bien que n’utilisant que 49 bits
pour son encodage, en utilisera en fait 56 pour son stockage et
sa transmission. On peut considérer ces 7 bits supplémentaires comme une
forme de hachage, mais comme c’est répartit tout au long du message, ça
n’est pas pratique à extraire et à utiliser globalement.
Le schisme de 1981 s’est déclenché lorsque des hérétiques décidèrent d’utiliser ce bit pour produire des ASCII étendus à 256 caractères blasphématoires. Chaque nouvelle secte produisant alors son lot de nouveaux caractères, pas toujours compatibles entre eux. IBM avec EBCDIC, les européens avec l’ISO-8859-1, certains occidentaux avec windows-1252, …
Après des années de conflits d’encodage, et d’utilisation d’outils de conversion (i.e.
iconv), 1991 marque la fin de la guerre avec une proposition œcuméniques de réunification des peuples : unicode, qui mettra des décennies à s’imposer.Depuis, les choses se son tassées et on peut enfin s’échanger des émoticônes sans avoir peur qu’ils soient mal décodés. Pour leur interprétation, par contre, on a pas tranché.
Mots de Parité
Dans certains systèmes, plutôt que de calculer la parité pour chaque mot individuellement, on la calcule globalement, en effectuant un xor bit à bit entre tous les mots. Le résultat est appelé mot de parité.
Avec un codage ASCII, on pourrait calculer un xor de toutes les lettres et ainsi produire un mot de parité sur 7 bits également. On peut voir ça comme faire un xor sur chaque colonne. Il s’agit alors d’un nouveau caractère ASCII qu’on peut ajouter au message.
| Lettre | ASCII 7bits |
|---|---|
| B | 1000010 |
| o | 1101111 |
| n | 1101110 |
| j | 1101010 |
| o | 1101111 |
| u | 1110101 |
| r | 1110010 |
| ! | 1000001 |
Ainsi, Bonjour, utilisant 7 caractères, peut
utilement être complété d’un 8ème caractère de
contrôle : !. Ce caractère pourrait être considéré comme un
hachage du message original. Bon, en vrai, on n’utilise pas cette
technique sur des caractères mais sur des mots bien plus longs.

Pour de vrai, en RAID. On utilise cette méthode lorsqu’on branche des disques durs en parallèle pour répartir les données. En RAID 3 (mais aussi 5, 6, …), un des disques contient le xor bit à bit des autres disques. Ce disque de contrôle a l’avantage de permettre de reconstruire entièrement un disque défaillant.
Ça marche parce que le xor avec les bits forment un groupe commutatif un peu particulier où n’importe quelle donnée est en fait son propre inverse. Dans notre cas, mettons que vous avez vos disques (notés ) et votre disque de contrôle (noté ) qui est le xor des autres, formellement, ça donne ça : Comme chaque donnée est son propre inverse, on peut aussi considérer que le xor des disques donne zéro : Comme l’opération est associative et commutative, on peut, en fait, calculer le xor dans n’importe quel ordre et on peut donc numéroter les disques comme on veut. Si un disque flanche, n’importe lequel mais je vais le nommer pour simplifier, vous pouvez re-ordonner la liste et ensuite inverser les équations précédentes : Et voilà 😃, vous pouvez reconstruire votre disque. En fait, une fois le xor fait, mathématiquement, les disques deviennent équivalents, chacun contrôlant l’ensemble des autres.
Sommes
Pour continuer, plutôt qu’un xor des mots du message, on peut aussi utiliser une somme des mots du message. On se rapproche alors de cette notion de somme de contrôle.
Puisqu’on travaille avec des mots de taille fixe, le résultat de la somme peut être plus long que les mots (à cause des retenues). Il faut alors choisir comment gérer ces débordements : les jeter silencieusement est souvent le plus simple, mais comme on va le voir, certains préfèrent les garder et en faire quelque chose.
Pour de vrai, IPv4. Lorsque vos ordinateurs communiquent sur le réseau à l’ancienne, ils forgent des paquets IP contenant, dans leur en-tête, l’adresse IP de votre poste, celle de la destination et tout un tas d’autres données sympas pour faire plein de choses amusantes.
Entre autre, le checksum. Pour le calculer, on coupe l’en-tête en mots de 16 bits (soit deux octets) qui sont ensuite additionnés. Ici, ce qui déborde est considéré comme un mot supplémentaire qu’on ajoute ensuite (et ainsi de suite tant qu’il y a une retenue, mais ça fini vite par s’arrêter). On appelle ça une « addition complémentée à 1 ». Le résultat est ensuite inversé (les deviennent des et vice versa). On appelle ça un complément à 1, d’où certaines confusions parfois. Le résultat est enfin inséré au bon endroit du message.
L’intérêt d’inverser ce checksum et que les routeurs qui recevront le message pourront simplement calculer un checksum de l’en-tête complète et contrôler que le résultat vaut bien zéro. Mathématiquement, le principe est similaire au xor des disques durs précédents.
Par exemple : Voici une capture réseau lors d’une
requête ping (techniquement, un ICMP Echo Request) de mon poste
(192.168.1.149) vers google.fr
(216.58.213.131), la partie concernant le protocole IP est
sélectionnée et contient, entre autre en-tête, la somme de contrôle
sélectionnée en bleu (ici, 0x6917).
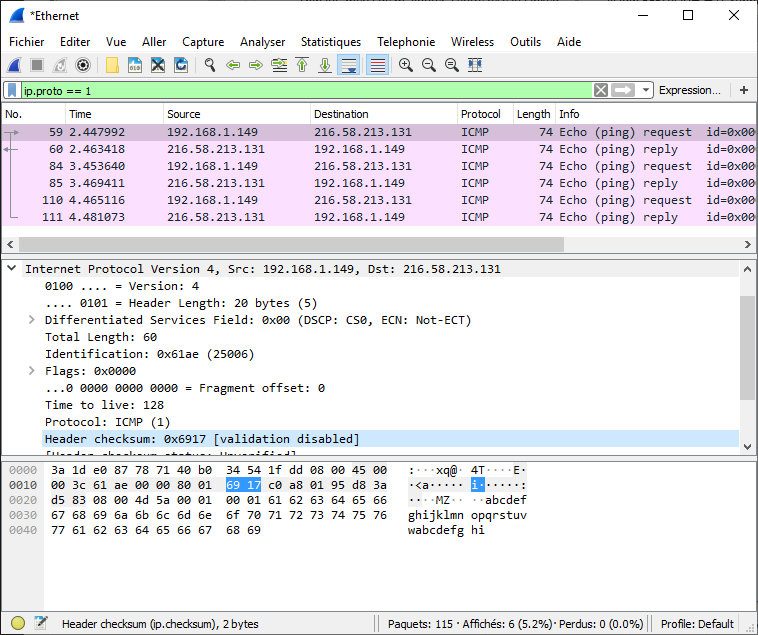
Si on veut s’assurer que l’en-tête est correct, il faut donc additionner tous les mots de 16 bits (soit 4 caractères hexadécimaux) de l’en-tête IPv4, sans tenir comptes des autres en-têtes (ici Ethernet et ICMP) ni les données (contenu de la requête ICMP). Le tout, en prenant en compte ces histoires de complément…
Le tableau suivant vous montre ce calcul :
| Entête (valeur) | Hexa |
|---|---|
| Version (4), Taille de l’entête (5), type (0) | 4500 |
| Taille totale (60) | 003C |
| ID | 61AE |
| Drapeaux et offset (0) | 0000 |
| TTL (128) et protocole (1 pour ICMP) | 8001 |
| Somme de contrôle | 6917 |
| Source (première moitié 192.168) | C0A8 |
| Source (deuxième moitié 1.149) | 0195 |
| Destination (première moitié 216.58) | D83A |
| Destination (deuxième moitié 213.131) | D583 |
| Total (avec débordement) | 3FFFC |
| Débordement seul | 3 |
| Total « complémenté à 1 » | FFFF |
| Complément à 1 | 0000 |
Et comme les choses sont bien faites, ce complément à 1 du total complémenté à 1 vaut bien zéro et le paquet est valide. Sans surprise puisque ces requêtes avaient reçu une réponse (ou plutôt un ICMP echo reply).
Notez que l’ICMP insère également un checksum calculé exactement de la même manière sur ses propres en-têtes.
En IPv6 les choses ont évolué et il n’y a plus de checksum.
Les ingénieurs ont en effet constaté que des vérifications d’intégrité étaient déjà faites par les couches inférieures, dites de liaison comme Ethernet ou le WiFi mais aussi par les couches supérieures, dites de transport comme TCP et UDP qui ont toutes deux un checksum (calculé exactement comme pour IP et ICMP) mais dont la portée déborde également sur une partie des en-têtes IP.
On aurait du, pour être propres, corriger TCP et UDP pour éviter de faire un checksum sur les en-têtes IP (puisqu’il s’agit de deux couches différentes, elles ne devraient pas dépendre l’une de l’autre) mais comme c’est très coûteux de changer un protocole et qu’il fallait trouver une solution à la pénurie des adresses IPv4 (on est dans les années 90), on a préférer ne modifier que la couche IP en produisant IPv6.
Divisions décimales
Le problème des méthodes précédentes, c’est que si certains mots sont déplacés dans un autre ordre, elles ne le détectent pas. C’est le principe des opérations commutatives, ça nous aide bien pour les disques durs, mais ça se retourne contre nous dans les autres cas.
Historiquement, ces nouvelles méthodes ont été développées pour des données numériques souvent manipulées à la main. Là où les précédentes veulent détecter une erreur électronique (un changement de bit), ici, on cherche à détecter les erreurs humaines, avec donc des inversions, des doigts qui se trompent, un oubli de chiffre…
Pour détecter ces erreurs de déplacements, l’idée est alors de remplacer la notion de somme par celle de division, en gardant le reste pour être exact (mathématiquement, on parle aussi de modulo). Car c’est lui qui est le plus sensible aux conditions initiales : un petit changement dans la donnée produira normalement un reste différent.
Tout l’art consiste donc à trouver les diviseurs permettant de maximiser les erreurs détectées ; changement de chiffres individuels n’importe où (et parfois des groupes de chiffres) et les inversions entre deux chiffres (côte à côte ou à une certaine distance).
En vrai, le numéro d’identification national. Ce numéro qui permet d’identifier une personne physique et lui rattacher des droits, et des devoirs, est souvent construit à partir de l’état civil.
- En France, on utilise un chiffre pour le sexe (1 pour les filles, 2 pour les garçons), quatre pour la date de naissance (2 pour l’année, 2 pour le mois), 5 pour le lieux de naissance (2 pour le département, trois pour la commune) et enfin 3 pour le numéro d’ordre.
- En Belgique, on utilise 6 chiffres pour la date de naissance (2 pour l’année, 2 pour le mois, 2 pour le jours) puis trois pour le numéro d’ordre (avec un compteur impair pour les hommes et autre pair pour les femmes).
Pour ces deux pays, suit alors une clé de validation () sur deux chiffres. Cette clé correspond au complément à 97 du reste de la division du nombre () précédemment formé par 97 :
Pour être tout à fait exact, en Belgique, si vous êtes né après l’an 2000, on va ajouter un 2 en début de numéro. Juste le temps des calculs puisque ce 2 n’apparaît pas officiellement dans votre numéro.

Par exemple. Si on prend le numéro de sécurité sociale d’exemple de la page de Wikipedia, une certaine Nathalie Durand, 157ème bébé née en mai 1969 dans une commune inexistante du Maine et Loire.
Son numéro d’enregistrement est donc 2 69 05 49 588 157. Si on calcule la division entière par 97, on obtiens le résultat suivant :
Soit un reste de 17. La clé étant en fait le complément à 97, on obtiens bien une clé de 80 comme suit :
On retrouve également un modulo 97 dans la norme ISO 7064, utilisée entre autre pour les numéros de comptes bancaires internationaux (IBAN). Après quelques manipulation (entre autre insérer une clé nulle) on calcule alors le complément à 98 du reste de la division par 97 :
L’avantage de cette méthode est, comme pour IPv4, que la vérification se fait en calculant une clé sur la donnée fournie (contenant déjà une clé valide, donc). L’intérêt d’utiliser 98 est qu’une clé calculée vaut au moins 1, différente de la clé vide insérée lors des calculs.
Divisions binaires
Avec des données binaires, on pourrait garder le même principe mais leur longueur et surtout la gestion des retenues deviennent pénibles à gérer. Pour simplifier tout ça, on va alors remplacer la somme par un xor qui a le bon goût de ne pas avoir de retenues. À programmer ou à câbler, c’est beaucoup plus pratique.
Mathématiquement, on change d’ensemble pour les calculs : plutôt que l’anneau habituel , on va utiliser . Le xor remplace la somme.
Par contre, même si le principe des calculs reste le même, vu qu’on change une des deux opérations de base, les résultats sont différents. Voyez par vous-même dans le tableau suivant où la première colonne est en décimal (avec astérisque comme opérateur $ *$ ) et les colonnes suivantes sont en binaire mais l’une avec la somme, l’autre avec le xor.
| ou |
De même, la division garde le même sens ; calculer l’inverse de la multiplication. Mais son calcul (et donc son résultat) change. Vous pouvez faire l’essais en posant vos divisions comme à l’école primaire.
Et comme pour les clés de validation des numéros d’identification, tout l’art de l’informaticien est de choisir un diviseur qui va maximiser les erreurs détectées. Entre autre, un diviseur utilisant bits aura toujours un reste qui tiens sur bits. Si vous voulez un reste sur 32 bits, il vous faut donc un nombre sur 33 bits.

En vrai, les CRC. Ces codes de redondance cyclique ont été inventés dans les années 60 et suivent ce principe de diviser une donnée, d’en garder le reste et de contrôler qu’il est le même que celui transmis.
Lorsqu’on parle de CRC, on associe des données binaires à des polynômes. Chaque bit du message étant le coefficient du terme polynomial correspondant. Voici quelques exemples :
| Coefficients | Polynome |
|---|---|
Plutôt que d’utiliser l’anneau , on utilise alors celui des polynômes à coefficients booléens . Les calculs et les données sont alors exprimés en termes de polynômes. Le diviseur choisi peut être considéré comme un générateur de tous les messages valides, et ce genre de chose.
Mais comme ça revient en fait au même, on peut rester sur des nombres sans introduire de .
Comme il y a pléthore de diviseurs possibles (dont beaucoup sont d’ailleurs utilisés), on a pris pour convention de nommer chaque cas par le terme CRC, suivi de la taille du reste (e.g. 32 lorsqu’il fait 32 bits) suivi du nom du diviseur lorsqu’il n’est pas celui par défaut.
Par convention, comme tous les diviseurs commencent par un
1et qu’il apparaît sur un bits en plus par rapport à la taille du reste, on ne l’écrit pas et on ne le mentionne pas. En fait, on peut même se passer de ce 1 pour faire les calculs…
Par exemple, le CRC-3-GSM est utilisé dans les
réseaux mobiles. Il utilise le diviseur 3 (en base 10, en
binaire, ça donne 11, et en vrai, on divise donc par
1011).
Autre exemple, bien plus connu, le CRC-32,
qui utilise, par défaut, le diviseur 0x04C11DB7. On
l’utilise, entre autre, dans les trames Ethernet (vos câbles RJ45), le
Sata, les archives gzip et les images PNG.
On a également utilisé ce CRC-32 comme contrôle d’intégrité pour le protocole WEP qui était sensé protéger l’accès aux réseaux WiFi. Parmi ses faiblesses, l’utilisation de ce CRC dans un contexte d’attaque informatique n’était pas adapté puisqu’un attaquant pouvait forger ses CRC pour ses paquets modifiés.
Et maintenant ?
Les fonctions de hachage sont en fait très nombreuses, tout comme leur utilisation. Par exemple, le ping google précédent met en fait en place au moins trois de ces fonctions pour vérifier l’intégrité du paquet transmis et reçu :
- Un CRC-32 en fin de trame Ethernet,
- Un complément à 1 d’une somme complémentée à 1 dans l’en-tête IP,
- Un autre complément à 1 d’une somme complémentée à 1 dans l’en-tête ICMP.
De même, un remboursement de l’assurance maladie utilisera une clé de contrôle pour votre IBAN et une autre pour votre numéro d’identification. Ces paiement utilisant les technologies de l’informatique et des télécommunications, je vous laisse imaginer le nombre de checksums calculés entre le moment où vous entrez chez votre médecin et celui où vous constatez le remboursement sur l’interface web de votre banque en ligne…
Et ça, ce ne sont que des sommes de contrôles, pour aller plus loin vous pouvez aller jeter un œil aux empreintes cryptographiques…