Sauvegarder ses données chez OVH avec Duplicati
Divulgâchage : Sauvegarder ses données, c’est important. Mais pas besoin de se prendre la tête. Aujourd’hui, nous vous montrons qu’il est relativement simple de planifier une sauvegarde automatique de ses données importantes dans le cloud d’OVH, grâce à Duplicati, un outil disposant d’une interface graphique plutôt bien pensée.
On ne le redira jamais assez, il est nécessaire d’effectuer des sauvegardes régulières de ses données importantes. Que ce soit un incendie ou un cryptolocker, le risque n’est jamais nul. Heureusement il existe des solutions peu chères et efficaces pour sauvegarder ses données. Alors pourquoi s’en priver ?

Jusqu’à présent, chez les arsouyes, nous utilisions duplicity, un outil en ligne de commande, qui nous permettait d’effectuer des backups sur le cloud d’OVH. Mais comme, au bout d’un moment, la ligne de commande ce n’est pas très user friendly, nous avons mis en place un nouveau serveur pour faire nos sauvegardes, cette fois, basé sur duplicati, qui permet de faire à peu près la même chose, mais cette fois-ci, via un interface graphique.
Pour sauvegarder les données, nous utilisons le stockage Public Cloud de chez OVH, et pour l’envoi des fichiers, le logiciel
duplicati, installé sur un Ubuntu Server à partir du.deb.
Parce qu’il faut l’avouer, visualiser ce qui a été sauvegardé juste en ligne de commande donne un listing imbuvable…
Côté OVH
Nous avons choisi d’utiliser OVH Object Storage comme stockage distant. Pas parce que l’on des actions chez OVH, mais parce que ce n’est pas très cher au Go (0.01€ HT/mois/Go), et que, puisqu’on a plusieurs services chez eux, ça évite de multiplier les prestataires.
Un espace de stockage de type «Object Storage» fait partie de l’offre professionnelle de OVH nommée «Public Cloud». Vous devrez donc effectuer une commande chez OVH, puis envoyer une copie d’une pièce d’identité avant que le service ne vous soit ouvert.
Une fois que votre commande est validée, vous pouvez vous rendre dans l’écran de configuration d’OVH, que vous retrouverez à partir du tableau de bord, dans l’onglet Public Cloud.

Le conteneur
Avant de pouvoir stocker quoique ce soit chez OVH, il faut créer un conteneur.
Pour cela, dans le menu de gauche, cliquez sur Object Storage, dans la section Storage.
Cliquez sur Créer un conteneur d’objets.

Vous arriverez sur un formulaire en trois parties, permettant de configurer votre conteneur.
La première chose à configurer est la zone géographique du conteneur. Par habitude, chez les Arsouyes, nous choisissions Gravelines. Choisissez la localisation qui vous convient, en fonction de votre situation géographique, et cliquez sur Suivant.
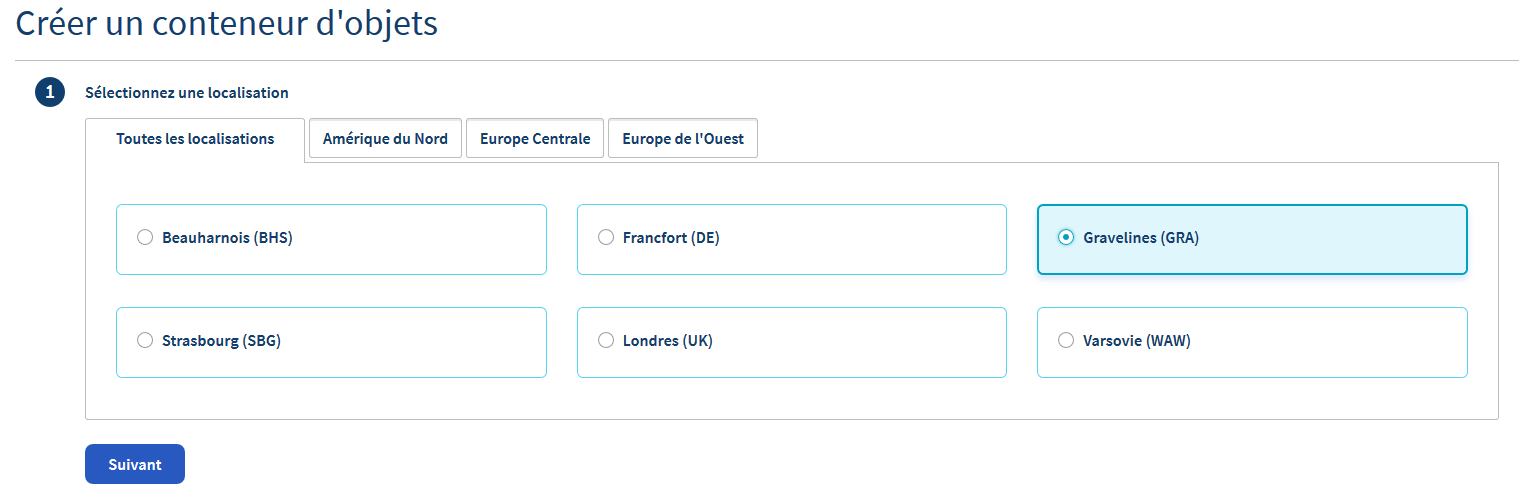
La deuxième chose à configurer est le type de stockage. Il existe trois types de conteneurs:
- Hébergement statique : utilisé dans le cas de l’hébergement d’un site web,
- Privé : utilisé pour stocker des informations d’archivage privée, non destinée à être disponibles sur internet,
- Public : espace de stockage pour des données destinées à être accessibles publiquement.
Choisissez Privé et cliquez sur Suivant.
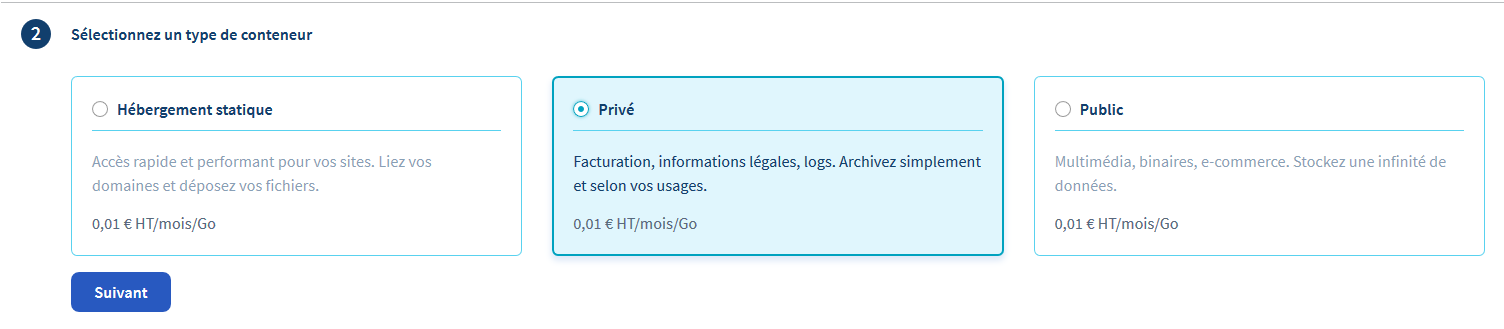
Enfin, donnez un nom à votre conteneur et cliquez sur Ajouter le conteneur.

Vous pourrez alors retrouver la liste des conteneurs créés dans l’interface de OVH.

L’utilisateur
Après avoir créé un conteneur, il vous faudra un utilisateur qui puisse y accéder et y déposer des données.
Pour cela, toujours dans l’interface de OVH, sous l’onglet Public Cloud, dans le menu de gauche, cliquez sur Users & Roles, dans la section Project Management.

Vous pourrez alors créer un nouvel utilisateur en cliquant sur Ajouter un utilisateur.

La première chose qui vous sera demandée est la description de cet utilisateur, afin de pouvoir le retrouver facilement dans l’interface d’OVH. Entrez une description et cliquez sur Suivant.
Cette description ne sert qu’à se repérer facilement l’utilisateur dans l’interface web de OVH. En fait, à la création de l’utilisateur, un nom sera généré aléatoirement par OVH, et ce sera celui-là que vous devrez utiliser pour vous connecter.
Afin de limiter les actions que cet utilisateur peut faire, vous devez lui assigner un rôle.
Notre utilisateur va être utilisé pour stocker et récupérer des données dans le conteneur en utilisant swift. Les seuls rôles correspondants à ce cas d’usage sont Administrator et ObjectStore Operator. Comme on préfère utiliser la politique du moindre privilège, il faut cocher la case Object Store operator.
Cliquez ensuite sur Valider.

Vous verrez alors apparaître un message en vert sur l’interface web, vous donnant le nom et le mot de passe assigné à votre utilisateur. Notez les précieusement, car il n’est pas possible de les récupérer après coup. Si vous ne le faites pas, ce n‘est pas dramatique, mais il vous faudra demander une régénération de mot de passe.

Information à l’attention des petits malins. Non les Arsouyes ne vous ont pas mis leur mot de passe en clair sur leur site. Nous avons bien évidemment créé un utilisateur spécialement pour faire les captures d’écran et l’avons supprimé ensuite 😉.
Informations OpenStack
On a notre conteneur, on a notre utilisateur. Tout est bon côté OVH.
Afin de simplifier la configuration de duplicati, nous
allons récupérer le fichier de configuration d’OpenStack fournit par
OVH, car il contient des informations qui nous servirons par la
suite.
Pour cela, dans la liste des utilisateurs sur l’interface d’administration de OVH (pour rappel, onglet Public Cloud, section Project Management, menu Users & Roles), cliquez à droite de l’utilisateur, sur la petit icone ronde avec les trois petits points.
Un sous-menu s’ouvre. Cliquez sur Télécharger le fichier RC d’OpenStack.

Vous devrez renseigner la région que vous avez choisi pour votre conteneur. Cliquez ensuite sur Télécharger.
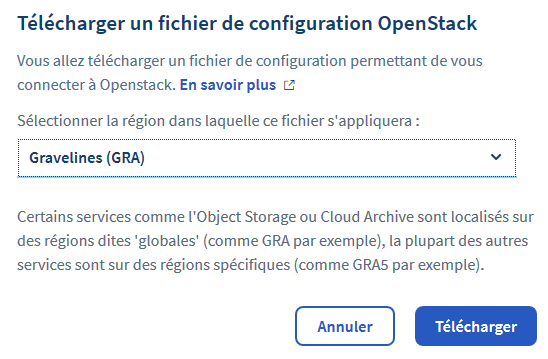
Il s’agit d’un fichier texte, à ouvrir avec un éditeur, afin d’en extraire les valeurs. On va donc gardez le fichier de côté, et on l’ouvrira lors de la configuration de duplicati.
Côté maison
Maintenant que tout est prêt chez OVH pour accueillir les données,
retour côté maison, pour installer et configurer
duplicati.
Installation
Nous avons choisi d’installer duplicati sur un Ubuntu
Server 20.04. Il n’existe pas de dépôt avec duplicati, il
faut donc télécharger le paquet debian et l’installer à
l’ancienne.
Le paquet ne gère pas les dépendances, et nécessitera l’installation préalable de quelques paquets :
sudo apt-get install mono-complete gtk-sharp2 libappindicator0.1-cil libappindicator3-0.1-cilRécupérez ensuite le .deb sur le site officiel. Au jour de
l’écriture de l’article, duplicati était en version
2.0.5.1-1. Il n’existe pas de lien latest, du coup, vous devrez
aller voir sur le site officielle la version en cours avant d’effectuer
le téléchargement.
wget https://updates.duplicati.com/beta/duplicati_2.0.5.1-1_all.debEnfin, installez le paquet via dpkg.
sudo dpkg -i duplicati_2.0.5.1-1_all.debSi une des quatre dépendances au dessus a été oubliée, vous pouvez utiliser la commande
apt --fix-broken installpour réparer votre installation.
Comme on ne souhaite pas lancer duplicati à la main,
nous allons l’installer en tant que service.
sudo systemctl enable duplicati.serviceAccéder à l’interface web
Nous avons installé duplicati sur un Ubuntu Server, donc
nous n’avons pas d’interface graphique. Ce qui pose problème puisque
duplicati marche de base de deux manière : via un programme
à lancer en interface graphique, ou via une interface web uniquement
accessible à partir de localhost.
Pour permettre l’accès à l’interface web aux autres machines, il faut
modifier le fichier /etc/default/duplicati et lui dire
d’écouter sur toutes les interfaces, en modifiant la ligne de
configuration DAEMON_OPTS :
DAEMON_OPTS="--webservice-interface=any".
Après un redémarrage du service, via la commande
sudo service duplicati restart, vous pourrez accéder à
l’interface web via l’url :
http://<ip de votre serveur>:8200
A la première connexion, duplicati vous avertira que si
vous êtes dans un environnement où plusieurs utilisateurs, il est
nécessaire de mettre un mot de passe afin d’éviter que les autres
utilisateurs puissent accéder à l’interface.
Cliquez sur Yes pour être automatiquement redirigés vers la page de configuration des paramètres.
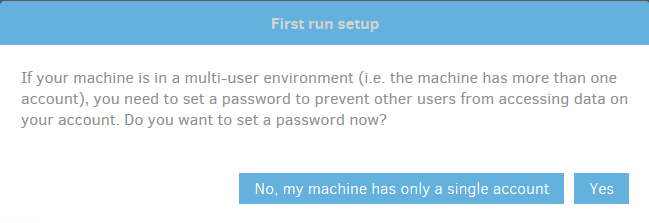
Pas de soucis si vous avez cliqué sur No, vous pouvez toujours changer d’avis à partir de la section Paramètres.
Afin de mettre un mot de passe, il faut cocher la case Mot de passe, puis l’écrire dans les zones Mot de Passe et Confirmer le mot de passe.

Notez au passage que Autoriser l’accès à distances est coché, ce qui est normal puisque vous avez déjà mis cette autorisation directement dans le fichier de configuration.
Cliquez sur OK en bas de la page.

Créer une sauvegarde
Maintenant que duplicati est installé, nous allons
configurer une sauvegarde.
Dans le menu de gauche, cliquez sur Ajouter une sauvegarde.
Choisissez Configurer une nouvelle sauvegarde. Cliquer sur Suivant.

Vous arriverez alors dans série de 5 écrans, chacun permettant de configurer un point particulier de la sauvegarde (paramètres généraux, destination, source, planification et options avancées).
Paramètres généraux
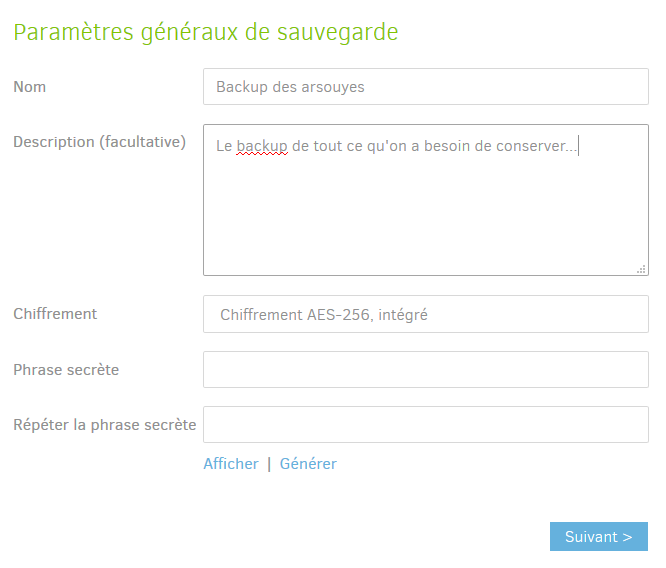
Le premier écran concerne les paramètres généraux :
- Nom : Le nom de votre sauvegarde, pour la retrouver
facilement dans l’interface de
duplicati, - Description: Si vous souhaitez expliciter un peu plus en détails ce que vous souhaitez sauvegarder,
- Chiffrement : Défini comment seront chiffrées les données avant leur stockage, bien utile si vous ne souhaitez pas qu’en cas de compromission de votre conteneur, vos données se retrouvent sur le net, choisissez Chiffrement AES-256, intégré,
- Phrase secrète: La phrase secrète pour le chiffrement,
- Répéter la phrase secrète : comme son nom l’indique, répéter la phrase secrète, pour être sûr que vous avez bien tapé ce que vous vouliez.
Cliquer sur Suivant.
Destination de la sauvegarde
Le deuxième écran va vous permettre de configurer où vous souhaitez sauvegarder les données. Par défaut, les données sont sauvegardées sur le disque dur du serveur.
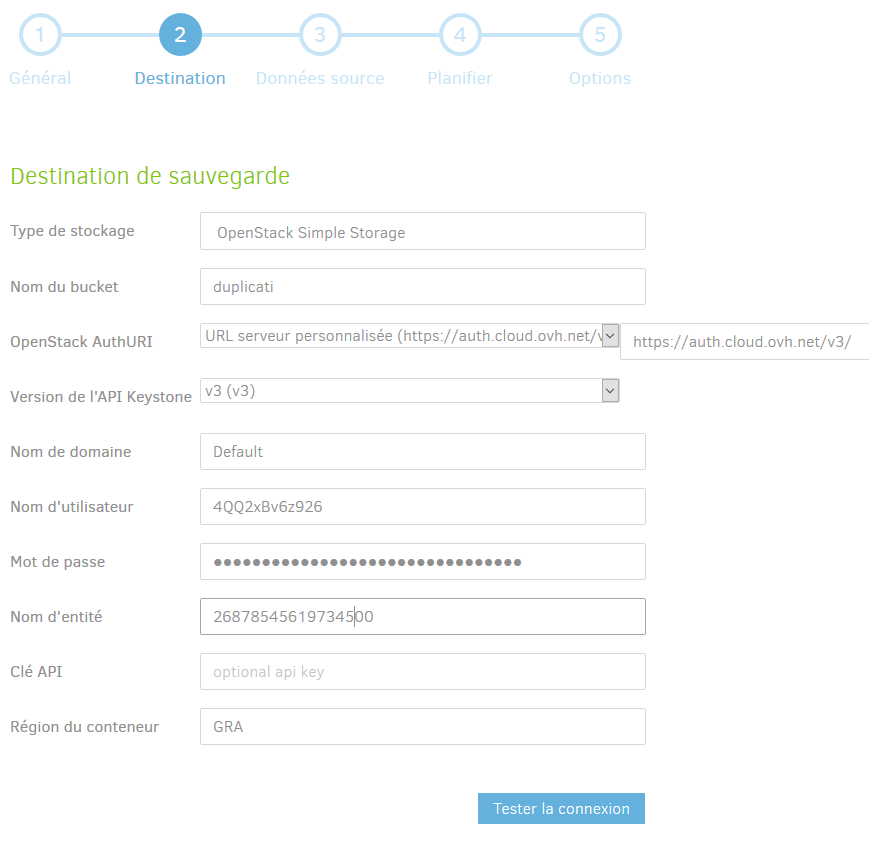
Nous, on souhaite les stocker dans le cloud de OVH, dans le conteneur que nous avons créé précédemment. Pour cela, il faut ouvrir la liste déroulante Type de stockage et sélectionner OpenStack Object Storage / Swift.
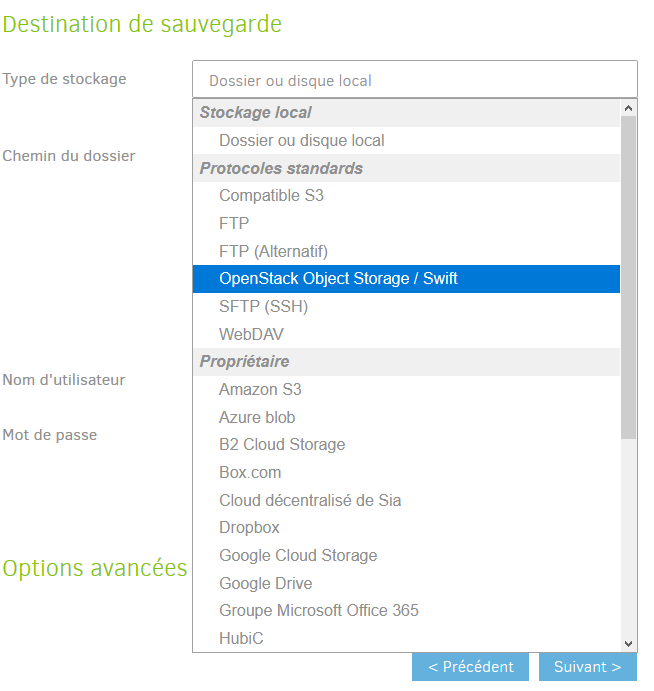
De nouveaux champs apparaissent, que nous allons compléter, entre autres, à l’aide du fichier de configuration de OpenStack que nous avons récupéré.
- Type OpenStack : Object Storage / Swift
- Nom de bucket : Le nom du conteneur que vous avez créé chez OVH. Nous l’avions appelé sauvegardes,
- OpenStack AuthURI : URL pour les appels à
OpenStack. Vous devez sélectionner URL serveur personnalisée()
et y renseigner ce qu’il y a sous
OS_AUTH_URLdans le fichier de configuration. Devrait être https://auth.cloud.ovh.net/v3/, - Version de l’API KeyStone : Version de l’API,
correspond à
OS_IDENTITY_API_VERSION, devrait être v3, - Nom de domaine : Mettre Default, en toutes lettres,
- Nom d’utilisateur : Le nom de l’utilisateur, celui
fournit par OVH lors de la création de votre utilisateur, correspond à
OS_USERNAME, - Mot de passe : Le mot de passe de votre utilisateur, donné par l’interface web et que vous aviez pris soin de noter,
- Nom d’entité : Notez ce qu’il y a sous
OS_TENANT_NAMEdans votre fichier de configuration, - Clé API : Laisser vide,
- Région du conteneur : il s’agit de la région que
vous avez sélectionné, dans notre cas, GRA, correspond à
OS_REGION_NAME.
OVH Cloud Storage fait partie des
AuthURIdéfinies par défaut dansduplicati. Malheureusement, ils s’agit de l’ancienne version de l’API (v2), et celle-ci n’est plus disponible depuis le 23 juin 2020 chez OVH. Il est donc indispensable de renseigner une URL personnalisée, ce qui n’est pas bien grave.
Cliquez d’abord sur Tester la connexion pour vérifier que vous avez bien tout renseigné. Si tout est bon, cliquez sur Suivant en bas de la page.
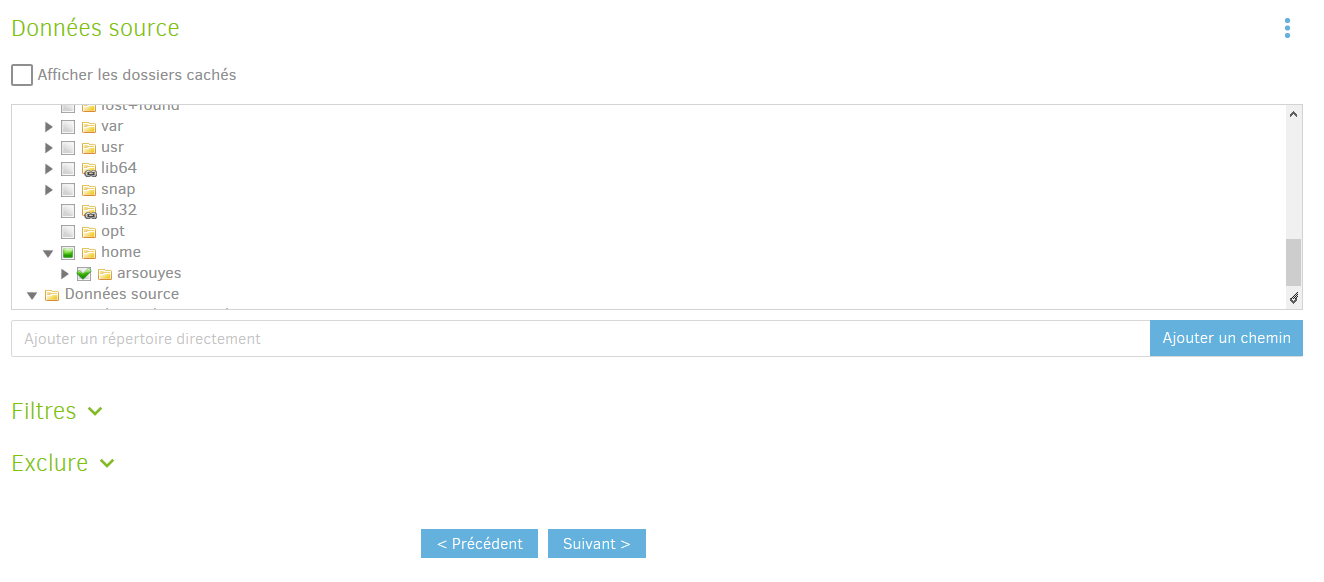
Données à sauvegarder
Le troisième page concerne les données que l’on souhaite sauvegarder.
Via un navigateur de fichier, il suffit de parcourir son disque dur, et de cocher les cases correspondant à ce que l’on souhaite sauvegarder. Il peut s’agir de documents en particuliers ou de répertoires.
duplicatimet à disposition des filtres pour exclure ou inclure certains fichiers, grâce à des expressions régulières, et des filtres préconfigurés permettant d’exclure les fichiers cachés, les fichiers systèmes, les fichiers temporaires ou les fichiers trop volumineux. Par exemple, lorsqu’il y a quelque chose que l’on ne souhaite pas sauvegarder, mais qui se trouve justement dans un répertoire coché, nous le préfixons par DoNotSave, et avons mis un filtre pour exclure tout ce qui commence par ce mot clef…
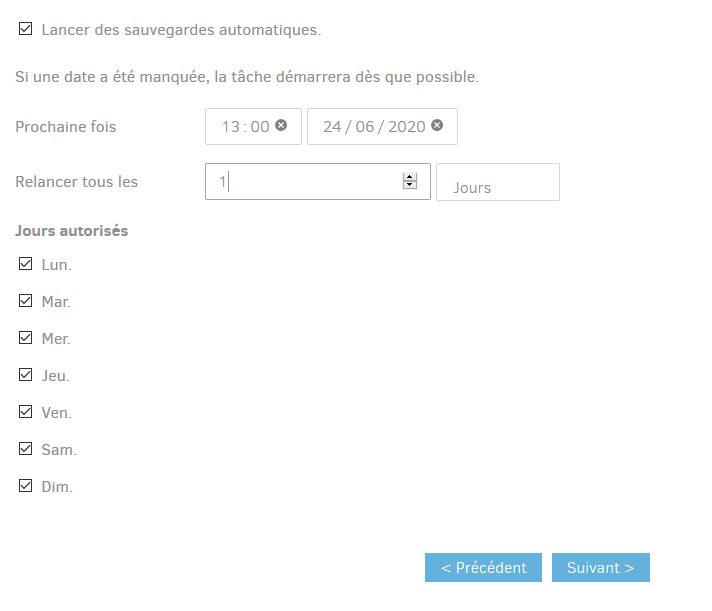
Planification
Le quatrième écran concerne le moment et la régularité des sauvegardes.
En cochant la case Lancer des sauvegardes automatiques,
duplicati se chargera d’effectuer la sauvegarde
régulièrement. Sinon, vous devrez les lancer à la main.
- Prochaine fois : Défini l’heure de la prochaine sauvegarde automatique. Cette heure sera utilisée comme base pour la suite (si vous demandez de lancer une sauvegarde tous les jours, ce sera cette heure qui sera choisie),
- Relancer tous les : Permet de définir la régularité. La première case vous permet de définir le nombre de fois, et la deuxième case l‘unité (minutes, heures, jours, semaine, mois, années). On peut donc demander «3 fois par semaines», «1 fois par an»…
- Jours autorisés : Si vous avez des contraintes, vous pouvez décocher les cases pour empêcher le backup certains jours de la semaine.
Cliquer ensuite sur Suivant.
Options
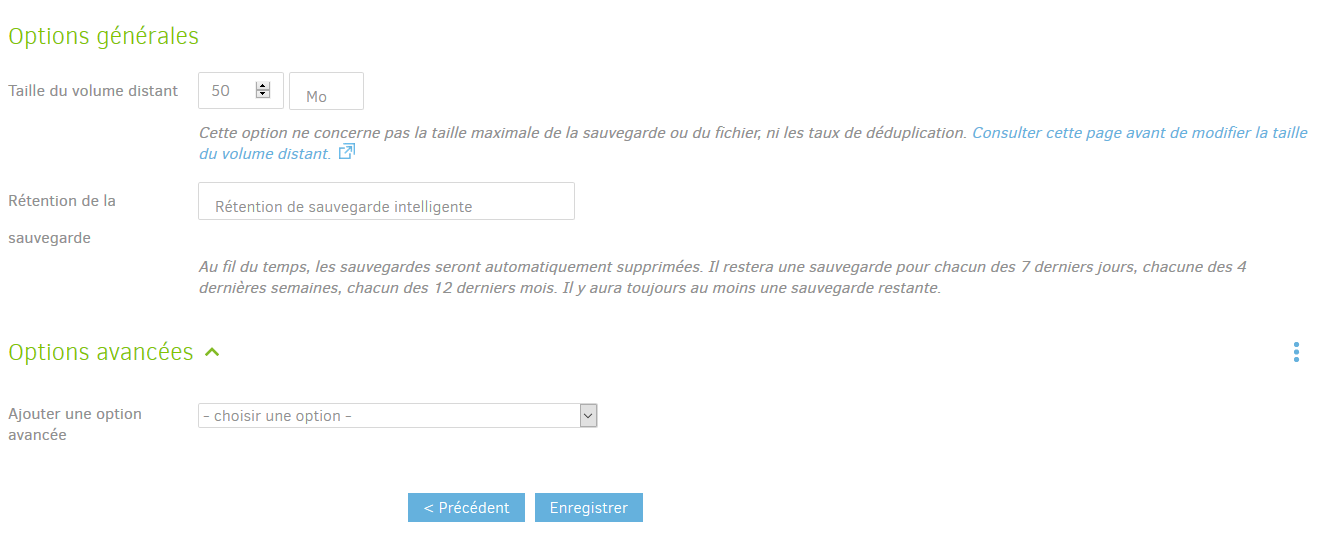
Enfin, la dernière page permet de définir quelques options un peu plus avancées :
- Taille du volume distant : permet de définir la taille des morceaux de fichiers envoyés,
- Rétention de la sauvegarde : permet de définir la
politique de rétention de la sauvegarde, i.e combien de temps
duplicativa garder quoi. Vous avez le choix entre :- conserver toutes les sauvegardes,
- supprimer les sauvegardes les plus anciennes (en fournissant un delta en jours, mois ou années),
- conserver un nombre spécifique de sauvegardes, les plus anciennes étant supprimées,
- sauvegarde intelligente : conserve 1 sauvegarde par jour sur les 7
derniers jours, une par semaine sur les 4 dernières semaines et une par
mois sur les douze 12 mois, il s’agit de la configuration recommandée
par
duplicati, - sauvegarde personnalisées : en entrant vous même ce que vous souhaitez.
- Options avancées : Il s’agit d’options très spécifiques à passer directement au serveur. Le mieux est de ne pas y toucher si vous ne savez pas ce que vous faites.
J’ai par exemple utilisé les options avancées pour demander à
duplicatide lancer un script spécifique avant toute sauvegarde. Bien utile si vous avez des données à rapatrier à partir d’un autre serveur au préalable.
Cliquer ensuite sur Enregistrer.
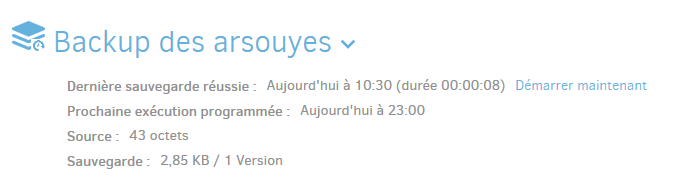
Vous serez finalement redirigés vers le tableau de bord où vous pourrez voir apparaître votre backup. Si vous ne souhaitez pas attendre la prochaine exécution programmée des sauvegardes, cliquez sur Démarrer maintenant.
Restaurer le contenu de ses sauvegardes
Admettons que vous ayez perdu un fichier et que vous souhaitez le restaurer.
Dans le menu de gauche, cliquez sur Restaurer.

Sélectionnez votre sauvegarde, dans notre cas Backup des arsouyes, et cliquez sur Suivant.

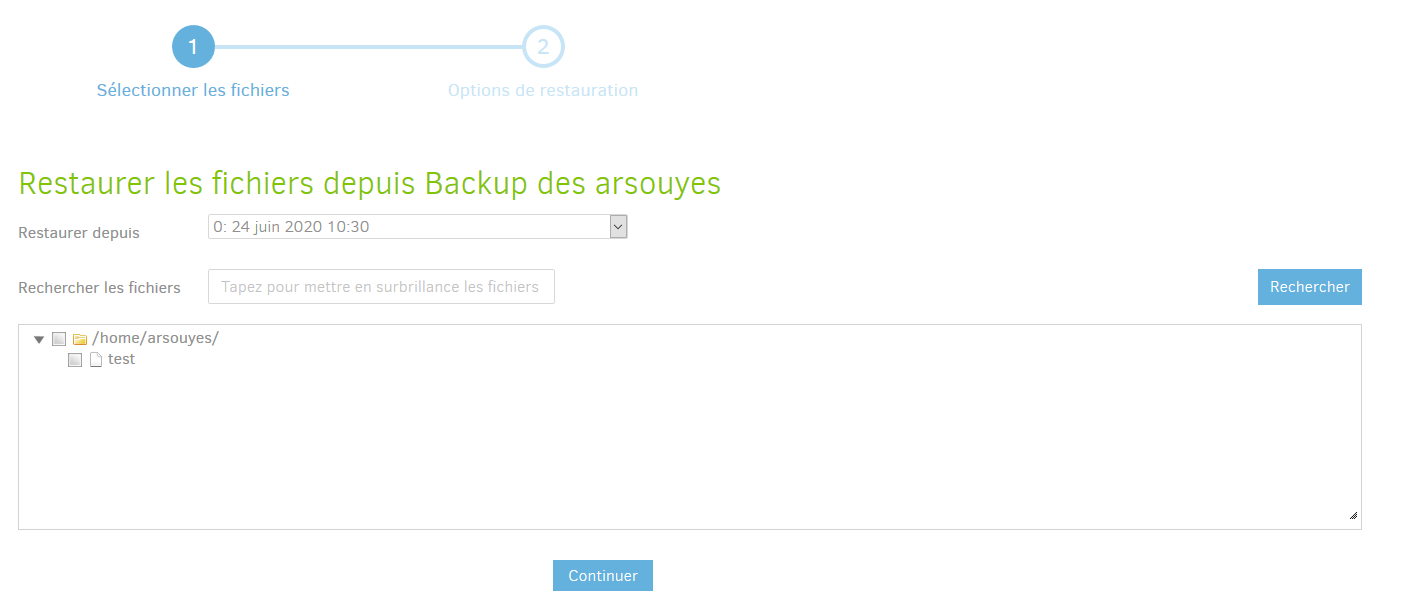
Vous devrez alors choisir ce que vous souhaitez restaurer.
- Restaurer depuis : Permet de choisir à partir de quelle sauvegarde vous souhaitez restaurer les fichiers, sélectionnez la date de la sauvegarde qui vous intéresse.
- Rechercher les fichiers : Permet d’effectuer une recherche, si vous souhaitez un fichier en particulier.
Cocher les cases correspondant aux fichiers que vous souhaitez récupérer. Dans notre cas, nous allons récupérer un fichier nommé test, et cliquez sur Continuer.
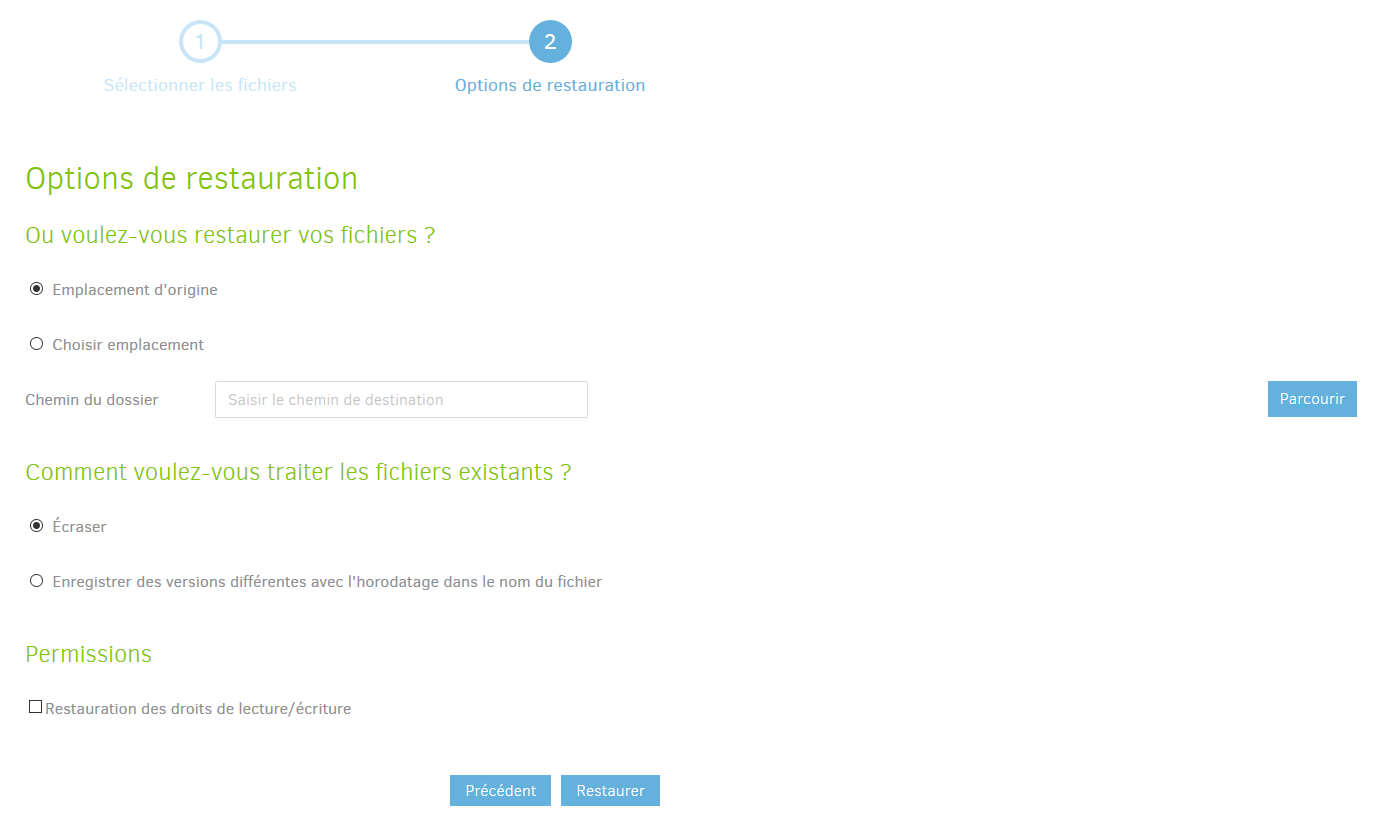
Ensuite, vous devrez définir où récupérer vos données, et comment.
- Où voulez-vous restaurer vos fichiers ?
- Emplacement d’origine : Restaure les fichiers à l’endroit même où ils étaient initialement,
- Choisir emplacement: Permet de définir un répertoire dans lequel seront restaurés les fichiers. Fournir un chemin.
- Comment voulez-vous traiter les fichiers existants ?
- Ecraser : Si le fichier existe déjà, il sera écrasé par celui de la sauvegarde,
- Enregistrer des versions différentes avec l’horodatage dans le nom du fichier : Comme son nom l’indique.
- Permissions :
- Restauration des droits de lecture/écriture : permet de restaurer les droits d’accès sur les fichiers.
Personnellement, j’ai pour habitude de restaurer mes fichiers dans un emplacement spécifique, et de les déplacer après coup dans le répertoire d’origine si besoin.
Cliquer sur Restaurer.
Et après
Si vous craignez de perdre des fichiers importants, vous disposez maintenant d’une sauvegarde à distante illisible pour l’hébergeur, mais accessible par vous de manière pratique et conviviale.
Vos données seront donc envoyées de manière régulière et automatiques et vous n’aurez plus à vous inquiéter. N’hésitez pas par contre à garder précieusement dans un coin le mot de passe de votre utilisateur OVH ainsi que votre passphrase. Sans ça, si votre serveur de sauvegardes crashe, vous ne pourrez plus récupérer vos données.